
Gartner:在中国大行其道的公有云服务为咨询与实施带来良机
ZD至顶网CIO与应用频道 03月29日 北京消息:Gartner 2016年首席信息官调查结果(参见图一)显示,云服务位列首席信息官选择及投资的中国前5大技术领域。由于中国政府的积极参与,公有云服务(IaaS)在中国的采纳度明显有别于其他国家。另一个不同之处在于,各个垂直行业的采购行为或需求相去甚远。为了更好的定位基础架构即服务的咨询与实施服务,技术业务部的领导者们必须深入了解中国政府与各企业的政策和最新计划。基于以下优先选择项目,我们预计到2020年,公有云服务将为服务提供商贡献至少15%的咨询与实施收入。
图一、2016年中国首要的技术优先领域
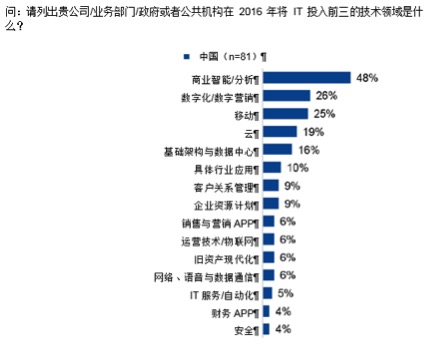
资料来源:Gartner(2016年12月)
受政府监管的中国公有云服务(IaaS)
中国监管机构不允许国外公有云提供商自行提供公共通信服务。这些提供商在构建数据中心与网络基础架构以及实施日常运营与交付服务方面均须严格遵守相关法规。国外公有云服务提供商侧重于交付技术与平台;而中国公有云服务合作伙伴则一般负责基础架构的日常运营与本地客户支持。
另一个监管重点与数据的本地处理及存储要求相关。此类法规目前适用于银行与金融企业,而今后将延伸至其他行业。近期全球趋势显示,对于敏感数据跨境流动的关注正日益增加。
采用中国公有云的客户只能通过中国证书登录,而无法利用同一证书登录其全球云基础架构,反之亦然。此外,本地公有云提供商可以构建自身的独立数据中心,但仍需要遵守其他数据安全相关政策。
公有云服务商通过合作伙伴提供基于公有云的企业级咨询与实施服务是最可行的方式
各种合作伙伴关系构成了公有云服务的应用生态系统。中国的公有云服务提供商面临多种选择;我们将其分为全球从业者、中国本土互联网公司、通信服务提供商(CSP)以及一些在特定领域拥有优势的服务供应商。根据企业机构的技术与业务需求来挑选适合的服务,对于企业首席信息官而言将至关重要。
虽然有些人可能认为公有云服务是一种商品,而且价格是唯一重要的考虑因素,Gartner认为市场内领先提供商之间的服务特性与配置也差别很大,因此价格不应是制定采购决策的唯一考虑因素。
咨询服务提供商生态系统可帮助企业评估不同公有云服务提供商的服务产品,洽谈合同并展开总拥有成本分析。
大部分中国公共云服务提供商一般先构建基准产品与服务,然后在其中添加更多功能特性时再考虑具体使用案例。它们通常不为客户提供定制化服务。
咨询与实施服务提供商应从合同的视角深入了解各种公有云服务提供商的产品与服务,以帮助客户躲避陷阱。此外,它们还必须具体了解定价模式、保障服务水平协议的方式、数据保护与存储等详细信息。
咨询和服务供应商应该了解各垂直行业对于公有云的应用程度度各不相同
公有云服务成熟度在不同垂直行业不尽相同,如:完善冗余系统或交付新服务。最近,许多中国企业对运行在公有云上的数字商务应用很感兴趣。然而,公有云服务提供商的产品与服务往往非常复杂,且功能繁多,因此需要专业技能才能实现最佳应用。许多IT企业机构并未充分理解关于原生云架构以及这些平台DevOps运营的最佳实践,而专业的咨询与实施服务可以有助于弥合技术缺口。
此外,各垂直行业可能已制定了行业指南,借以充分利用与中国“十三五”规划相关的新兴技术。例如,中国银监会于2016年7月15日发布了《中国银行业信息科技“十三五”发展规划监管指导意见》。而且,所有银行均须协作建立行业性公有云平台。
一般而言,公有云服务提供商将提供云基础架构与支持服务,支持各企业通过云平台运行其应用,从而赋予客户可扩展性与敏捷性优势。公有云服务商不会提供以下服务,而这为咨询服务提供商带来了大好机会:
- 公有云服务供应商的选择与评估
- 关于公有云服务的合约谈判
- 各垂直行业的最佳实践与经验教训
- 在利用公有云或私有云服务时确立云部署战略
- 定义从传统IT基础架构到公有云或从私有云到公有云的迁移战略
- 通过公有云服务提供数据安全、风险评估、IT治理解决方案的咨询
- 定制服务水平协议。例如,公有云服务商不提供99.999%的服务保证,而咨询服务提供商可在此方面协助客户
- 本地与全球云平台的无缝对接
好文章,需要你的鼓励


Netgear推出AI驱动网络管理平台,助力中小企业与服务商
Netgear发布云端网络管理平台Insight 10.0,引入AI驱动能力,专为中小型企业(SME)和托管服务提供商(MSP)设计。新版本提供智能运维、统一可视化、简化管理及云原生架构四大核心升级,支持自动化故障排查、设备健康监控及多站点集中管理,帮助IT团队从被动响应转向主动运维,解决中小企业长期缺乏企业级网络管理工具的痛点。

北京航空航天大学研究团队揭秘:给AI代码助手加几行“路标注释“,导航效率提升了多少?
北京航空航天大学研究发现,向AI代码助手注入轻量级结构注释,可使Bug定位准确率提升2.2%,运行轮次减少1.6次,且运行结果方差减半。

旧笔记本、台式机与打印机该如何正确回收处理
许多人将旧电子设备堆放在储藏室或车库中,而非妥善处置。实际上,回收旧电脑和打印机既简单又通常免费。Best Buy、Staples等大型零售商均提供免费电子废品回收服务,每日可接收多台设备。在回收前,务必通过恢复出厂设置或专业工具彻底清除个人数据。如无零售店,可通过Earth911或消费技术协会的在线工具查找附近的回收中心。

北京大学与DP Technology联手:用135M参数模型打败十亿参数级竞争者,像素级图像生成迎来新突破
北京大学与DP Technology提出PRA框架,通过16维低维中间状态与并行解码像素输入,同时解决像素空间自回归图像生成的高维预测误差和训练推断差距两大瓶颈,135M参数超越19亿参数模型。
2017
03/29
15:41
分享
点赞

pgEdge推出ColdFront,加入OLTP与OLAP融合赛道以支持AI应用
TabFM:面向表格数据的零样本基础模型正式发布
Netgear推出AI驱动网络管理平台,助力中小企业与服务商
旧笔记本、台式机与打印机该如何正确回收处理
美国NRC提出核废料处置新规,为长期搁置问题开辟出路
OpenClaw 智能体正式登陆 iOS 与 Android 平台
智引芯程,定义未来:德州仪器亮相 2026 慕尼黑上海电子展
“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
Gartner预测到2030年,新云提供商将占据2670亿美元AI云市场20%的份额
Gartner:数据智能体应用兴起,真正自治尚在路上
Gartner划出五条赛道,中国AI正在集体提速
Gartner发布2025-2030年可能被忽视的七大颠覆性变革
Gartner:2026年全球IT支出预计将增长13.5%,达到6.31万亿美元
Gartner:中国“十五五”规划下的CIO行动建议
Gartner提出三大要素助力企业基于新的 AI 基础设施部署大语言模型
Gartner:助力中国I&O负责人打破监控孤岛
Gartner发布三大AI价值实现路径
Gartner预测,在AI组合中纳入中国 LLM 和多模态模型的全球企业占比,将从 2025 年的5%上升至2027年的50%
