
Gartner:数据中台的价值兑现 孵化核心数据分析能力
随着“数据中台”(data middle office, DMO)的普及,中国企业机构希望能更好地管理和利用数据中台背后的数据资产。数据中台早年在一些领域的成功案例使得整个市场对这一概念抱有过高的期望。如今,大多数企业机构仍然认同DMO的概念,但同时也在寻求适当的方法将其应用于实践。另一方面,根据Gartner最近的一项调研(见图1),超过三分之一的企业机构依然对这一概念的可行性和适用性感到困惑。
图1:中国企业对于建设数据中台的态度
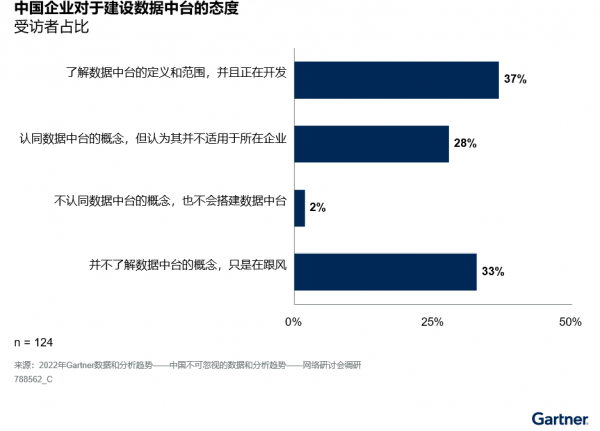
而今数据中台这一术语在市场上已逐渐淡化。终端用户和技术提供商两方对数据中台的关注点,都已从概念本身转向最终能实现的数据价值和所需要的能力。为确保顺利向DMO过度,企业机构必须优先考虑以下三个事项。
明确数据中台的价值主张
DMO的主要目的是实现数据一致性和可复用性。这些能力进而可以支持敏捷的数据驱动式管理和组装式D&A服务/产品,以实现业务优化和进一步的数字化。然而,数据中台并非一个颠覆性的技术或工具,也不是一个可以在短期内完成的单一项目。相反,它是一种D&A战略设计,可以通过利用一系列技术和业务实践,将它们与企业机构的整体业务战略挂钩,从而服务于不同的业务重点。
在市场中,“数据中台”是一个总括性术语,包含了D&A基础、D&A标准化以及D&A变现这三个主要数据价值主张的各个方面。Gartner定义了D&A领域的三种基本价值主张——基础设施、业务赋能和转型驱动——三者的收益水平呈渐进式增长。这一价值主张框架也可以视作DMO演进的各个阶段。
根据不同客户的成熟度阶段,DMO带来的价值认知和能力体现不同。信息化水平、数据就绪度和D&A素养水平将成为评估企业数据中台部署能力和部署空间的重要维度。此外,随着业务复杂性和业务规模的增加,数据中台的优势将变得更加明显。
需要注意的是,数据中台并不是为小型企业或业务内容稳定不变的企业而设计的。这类企业机构的D&A领导者应更多地关注较为精简地或具有针对性地D&A项目,从而快速实现业务回报。
根据优先级划定数据中台的范围
在确定了价值主张并了解组织当前状态后,企业机构就可以开始根据目标重点来确定需要实现的数据中台的范围。以往,数据中台一直被视为一个资源密集型的综合性D&A平台,由多个模块构成。但其实,企业机构并非一定要抱着这样的看法,从头开始搭建一个端到端的DMO。
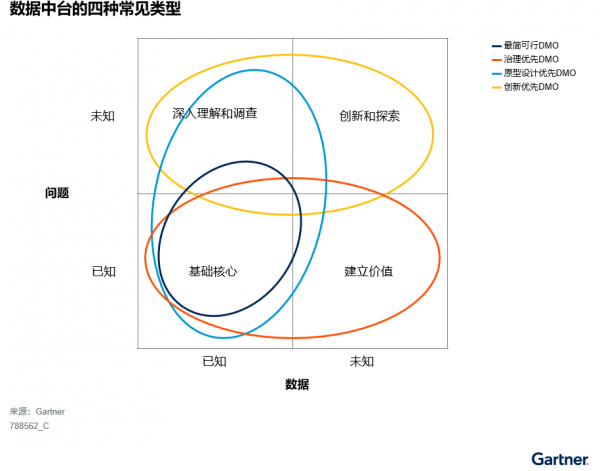
对于数据中台的扩展范围以及是否应该覆盖整个D&A平台,各方观点不一。供应商通常根据自己技术产品的优势来营销数据中台。然而,D&A领导者应根据自身的目标和优先任务、现有D&A架构和生态系统以及资源配置,确定数据中台的技术范围。图2展示了Gartner观察到的不同企业机构中最常见的四种关注类型。
图2:四种常见的数据中台类型
超越技术层面,推动数据中台的长期成功
尽管D&A领导者可以轻松地捕捉和呼应数据中台地概念,但在企业内部地推广中仍有挑战。与纯粹的技术项目不同,数据中台的成功很大程度上取决于业务部门和业务受众的积极参与和协作。然而,在许多情况下,业务用户会将DMO也视为纯粹的技术项目,例如部署数据仓库、部署报表平台或启动数据治理平台。因此,他们错误地认为DMO“应该”不需要他们过多的参与。业务部门对此缺乏共识和理解,是很多企业机构部署数据中台失败的原因。同时,这也会削弱企业机构内部对D&A项目的信任。
为避免这些情况发生,D&A领导者应利用敏捷交付方法,将D&A组织模式重塑为融合团队架构;建立具体的业务价值流程图;并设置级联指标以跟踪进展。
好文章,需要你的鼓励


Aqara Hub M200为HomeKit带来Matter支持和新自动化选项
Aqara Hub M200是进入Aqara生态系统的新入口,作为支持Matter的Zigbee 3.0中枢,可将传感器、开关、按钮等配件通过Matter共享到HomeKit。相比Hub M3设计更紧凑,支持2.4和5GHz双频Wi-Fi。M200充分利用Zigbee协议的低成本优势,让用户以更实惠的价格构建智能家居,同时享受完整的HomeKit功能。对于HomeKit用户来说,这是一个稳定可靠的桥接方案。

训练AI画画,一半数据就够了?港大团队发明“炼金术师“让AI挑食变聪明
香港大学团队开发的"炼金术师"数据筛选系统,能从海量图片中精选一半高价值数据,训练出比使用全量数据更优秀的AI图像生成模型。该方法通过观察模型学习反应判断数据价值,发现适度复杂的图片比简单图片更有训练效果,实现了5倍训练加速和显著性能提升。

LG智能电视强制安装Copilot快捷方式引发用户不满
LG电视通过系统更新强制安装微软Copilot快捷方式引发争议。虽然LG承诺将允许用户删除该图标,但仍计划在webOS系统中深度整合Copilot功能。三星等厂商也在推进类似AI功能。专家指出,智能电视内置聊天机器人会增加隐私追踪的复杂性,加剧系统臃肿问题。当前智能电视行业正通过用户追踪和广告实现软件盈利,消费者应关注隐私保护问题。

AI语言模型训练的“激励难题“:哥伦比亚大学揭示强化学习的探索与利用悖论
哥伦比亚大学等机构研究团队发现,在AI模型的强化学习训练中存在一个悖论现象:阻碍探索和阻碍利用竟然都能提升性能。研究揭示了裁剪技术实际是熵调节器而非学习信号,策略熵与性能无直接因果关系,并提出奖励错配理论解释随机奖励的积极效果,为AI训练方法设计提供了新的理论基础。
2023
03/29
15:19
分享
点赞

千问C端事业群成立后首推平价AI眼镜:低至1999元,搭载千问AI助手
Aqara Hub M200为HomeKit带来Matter支持和新自动化选项
LG智能电视强制安装Copilot快捷方式引发用户不满
Palo Alto Networks与谷歌云签署数十亿美元AI合作协议
OpenAI 获百亿美元融资与AI投资热潮持续升温
Meta计划2026年发布新一代图像视频AI模型
数字孪生联盟推出四个全新测试平台
BT:英国量子技术发展下一阶段取决于网络建设
Kodiak AI利用自动驾驶技术和物联网连接变革货运行业
Oracle和OpenAI数据中心项目获密歇根州监管机构批准
Optera室温光谱烧孔光学存储技术突破
英特尔助火山引擎“优化”AI云技术内核
