
Gartner:利用模型护栏规范GenAI的行为和输出
当前,许多企业机构都在全力推进生成式人工智能(GenAI)解决方案的设计和实施,希望提升解决方案的通用性和创造性,进而推动业务价值。2023年Gartner企业人工智能(AI)调研揭示了GenAI用例的三种最主要的实现方法,74%的受访者通过对现有GenAI模型进行定制化调整来满足自身用例的需求,65%的受访者尝试自行训练定制GenAI模型。
然而,实施GenAI绝非易事。对于创造性和通用性的追求,往往会增加GenAI解决方案的复杂性、不确定性和生成非预期结果的可能性,而这也成为了GenAI企业采用面临的主要问题。GenAI解决方案的创造性和通用性越强,出现非预期行为和输出(如幻觉、有害内容超出应用范围的内容等)的可能性越高(见图1)。
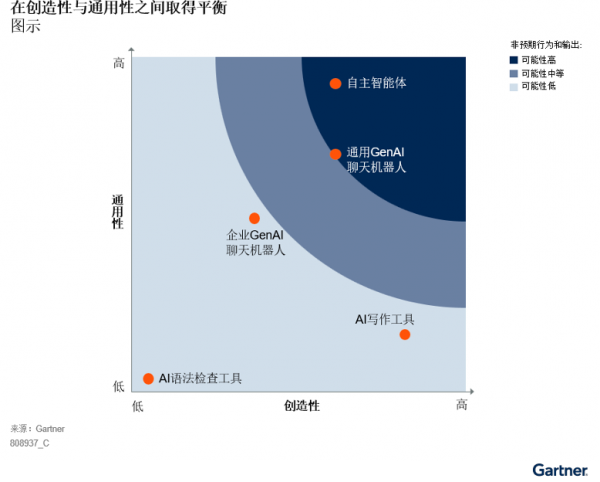
图1:在创造性与通用性之间取得平衡
选择基于GenAI模型自行构建GenAI解决方案的企业机构,其负责AI工作的数据和分析(D&A)领导者应利用开源护栏、商业护栏和自建护栏这三种护栏工具来控制GenAI模型的输入和输出,验证并矫正GenAI模型的输入和输出,提高模型的可靠性。
评估并优化GenAI解决方案的创造性和通用性
GenAI模型可兼具创造性和通用性。企业机构通常需要在广泛的场景中使用GenAI解决方案,而这些场景对于解决方案创造性和通用性的需求各不相同。因此,必须根据部署目的和具体场景下的功能需求,确定GenAI解决方案的定位,并根据在创造性和通用性两个方面的具体需求,利用护栏工具建立控制策略和机制。
负责AI工作的D&A领导者应基于GenAI解决方案的使用场景和方式,确定相应的业务风险容忍度,具体取决于:
- 业务用例的重要性
- 用于内部用途还是面向客户
- 是否引入了人工监督
而后,应根据业务风险容忍度,利用护栏工具管理模型输入和输出,建立严格或宽松的控制机制,并最终在创造性和通用性之间取得最佳平衡。
利用模型护栏验证和矫正模型的输入和输出
使用护栏工具,是管理GenAI模型创造性和通用性的一个切实可行的方法。护栏(在GenAI模型和应用与最终用户之间建立防护层)可以监控和管理模型的全部流量,包括用户输入和模型/应用输出(见图2)。
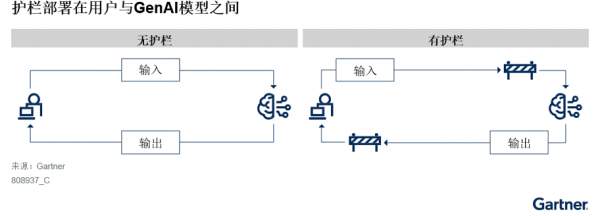
图2:护栏部署在用户与GenAI模型之间
以下是两种典型护栏:
- 用于控制最终用户输入的模型护栏:所有用户请求都必须经护栏过滤,以清除非预期的请求,包括超出GenAI解决方案应用范围的请求和违反可接受使用政策的请求。通过这种方式,护栏可以将解决方案的通用性控制在可管理的范围内,就像建立了一个安全围栏。
- 用于控制GenAI输出的模型护栏:所有模型输出都必须经过护栏的验证,但不同的用例对于模型创造性的需求存在差异,因而需要对模型施加不同程度的控制。但是,对于开发GenAl驱动的企业级搜索引擎或面向客户的聊天机器人的情况,必须对模型输出进行更为严格的验证和控制,以调节模型的创造性,并确保最终用户可以得到可靠且符合预期的结果。
需要注意的是,护栏并非“灵丹妙药”,不能完全解决GenAI解决方案的行为和准确性问题。GenAI解决方案必须在准确性与企业机构的风险承受能力之间取得平衡。
此外,伴随GenAI的快速发展,护栏技术也在不断变化和改进。鉴于神经网络的不可预测性,护栏技术目前是验证和矫正GenAI模型输出的一种切实可行的方法。长期来看,在基础GenAI模型变得足够可靠和可信之前,护栏提供了一种过渡解决方案,可以帮助企业机构推动GenAI采用。
好文章,需要你的鼓励


图灵奖得主Patterson:摩尔定律的真相,CPU、GPU、TPU的诞生与分工
2026年7月13日,软件工程师Ryan Peterman在他的播客The Peterman Pod上发布了一期与David Patterson的长对话。

NVIDIA推出“三模式“AI语言大脑:一个模型同时兼顾速度与准确,彻底打破现有推理瓶颈
英伟达推出Nemotron-Labs-Diffusion三模式语言模型,将逐字生成、并行扩散与自猜自验融于一体,单用户吞吐量最高达Qwen3-8B的4倍,同时保持相近准确率。

豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

华东师范大学等多家机构联合出手:让机器人训练数据“少而精“,原来靠这个秘密武器
SIEVE是一种面向机器人模仿学习的数据筛选方法,通过发现可复用行为原语和转换接口,用50%数据和训练量超越全量训练效果。
2024
09/10
10:07
分享
点赞

Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber、Wayve与Waymo的伦敦无人驾驶出租车大战即将开启
Mobileye计划2027年在美国推出自动驾驶出租车服务
Waymo召回近4000辆无人出租车,原因是其进入高速公路施工区域
特斯拉在奥斯汀开始测试无方向盘无踏板Cybercab量产版
图灵奖得主Patterson:摩尔定律的真相,CPU、GPU、TPU的诞生与分工
Omdia报告:Dell PowerProtect助力企业三年期网络弹性TCO最高降低61%
“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
