
人工智能能够构建一个自主驱动云吗?
企业和组织可以从云计算中受益,但许多公司并不希望面对公共云的成本,性能和治理问题,并且认为构建自己的私有云的复杂性和运营开销并没有那么困难。
如今,一些云计算供应商正在使用人工智能(AI)来简化私有云的部署和管理,使得云计算可以自主驱动(即自我安装,自我修复和自我管理)。在文中,将介绍自主驱动云的要求以及如何实现。
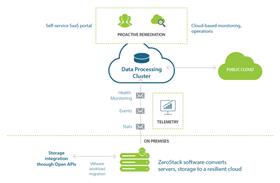
自主驱动云需求
就像这个领域的任何其他技术一样,人们需要几个系统一起工作,处理自我监控,愈合,学习以及创建自我优化模型。
这里列出了需要在自主驱动云中使用的技术:
•自动安装和配置:
第一步是安装过程,不需要太多的人为干预。云计算的构建块是服务器,存储和网络。使用超融合系统,将服务器和存储设备组合在一起,需要一个软件定义的网络,以尽量减少对物理网络的变化的依赖。
所以,第一个要求是采用服务器+存储构建块,其中预先安装了所有软件,并将其拷贝到操作系统映像中。用户只需要映像一些服务器并加载它们。一旦完成,云计算应该自动出现,而无需管理员知道有关各种服务和持久存储的任何内容。图像软件应该将服务器,存储和网络资源集中在一起,以创建高度弹性的云。
•与其他云计算和内部系统集成:
云计算不应该孤立工作,所以人们应该能够快速将其与现有的虚拟化基础架构和其他公共云连接起来。更好的是添加现有的存储系统,并通过开放(即RESTful)API将其作为云计算的一部分。这是一个可选的步骤,但如果要利用现有的存储和服务器投资,这一点非常重要。同样,大多数用户也希望与AD/LDAP集成,并拥有单一的用户和认证来源。
•以自助服务方式部署应用程序:
任何云计算的目标是为用户提供能够以自助服务方式被各种团队使用的IaaS和PaaS平台。例如,开发人员可以将其用于应用程序开发,持续集成/持续开发(CI/CD);支持团队可以使用它来提供用户环境的副本来解决任何支持问题;销售可以带来快速的PoC试用,最终IT可以提升各种应用的分期或生产部署。这些步骤需要完全自动化,以便人们可以重复它们,而不用花太多时间。任何云计算解决方案都应提供具有预构建应用模板的自助服务界面,以便快速部署。
•实时监控事件,统计,记录,审核:
由于云计算是共享环境,所以需要能够实时监控各种事件,统计信息和仪表板。需要知道应用程序的状态以及其他用户执行的操作。应该能够获取日志并审核所有用户的操作。例如,如果一个服务在晚上10点以后关闭,需要知道用户或脚本是否错误地关闭提供该服务的虚拟机。
•自我监测和自我修复:
任何像云计算一样复杂的系统都需要监视所有关键服务,并帮助监控工作负载。如果任何硬件组件或软件服务失败,系统应该检测并修复这种情况。然后,它可以提醒管理员哪个组件失败。如果这是硬件组件,如服务器,硬盘,SSD或NIC,则管理员可以采取纠正措施来恢复系统的容量。这是自驱动云计算的最低要求。
•长期决策机器学习:
由于自愈层负责短期决策,人们需要另一层自动化功能,可以在更长的时间内观察云计算和应用程序,以帮助优化云,提高效率并为未来做好计划。自主驱动的云平台收集遥测或操作数据,并利用机器学习来指导数据科学家如何开发现在为此行为建模的算法。这些算法可帮助用户做出决策。
该层应该观察预测能力建模和订购新服务器的用法。它还应该根据CPU,内存和I/O比例来确定要添加什么样的服务器。例如,如果应用程序的CPU密集度较高,那么应该对具有更多内核和更少存储空间的服务器进行排序。另一个领域是根据利用率帮助优化虚拟机的大小。
好文章,需要你的鼓励


苹果48GB M5 Pro MacBook Pro创历史新低,直降300美元
B&H近期对多款M5 Pro MacBook Pro机型推出300美元优惠。14英寸M5 Pro版本(48GB内存+1TB固态硬盘)现售价2299美元,较原价2599美元节省300美元,且该配置在亚马逊无法购买,折扣机会更为难得。此外,16英寸M5 Pro版本(64GB内存+1TB固态硬盘)同样享有300美元折扣。B&H在多款高配MacBook机型上的定价已低于亚马逊,是近期可找到的最优价格。

AI助手越权了?南加州大学等机构揭示大模型代理的“权限失控“问题
FORTIS是专门测量AI代理"越权行为"的基准测试,研究发现十款顶尖模型普遍选择远超任务需要的高权限技能,端到端成功率最高仅14.3%。

Insta360 GO 3S复古套装:怀旧美学与4K影像的融合
Insta360推出GO 3S复古套装,将现代4K运动相机与胶片时代美学结合。套装核心仍是仅重39克的GO 3S,新增复古取景器、胶片风格滤镜、NFC定制外壳及可延长录制时长至76分钟的电池组。复古取景器模仿老式腰平相机设计,鼓励用户放慢节奏、专注构图。相机内置11种色彩预设及负片、正片等滤镜,同时保留FlowState防抖、4K拍摄及10米防水能力,面向热衷复古影像风格的年轻创作者。

荷兰Nebius团队:给AI“起草员“瘦身,大模型推理速度最高提升5倍的秘密
荷兰Nebius团队提出SlimSpec,通过低秩分解压缩草稿模型LM-Head的内部表示而非裁剪词汇,在保留完整词汇表的同时将LM-Head计算时间压缩至原来的五分之一,端到端推理速度超越现有方法最高达9%。
2017
04/11
10:31
分享
点赞

CarPlay 新增两款音频应用,让你的旅途更精彩
Insta360 GO 3S复古套装:怀旧美学与4K影像的融合
谷歌免费存储空间调整:未绑定手机号仅享5GB
美国三大运营商携手卫星技术,向信号盲区宣战
Flytrex无人机携手达美乐,可一次性送达两个大号披萨
欧洲最大3D打印公寓楼提前数月竣工
彼亚乔携手迪士尼推出Grogu主题自主跟随货运机器人
Okta将AI智能体安全管理扩展至Amazon Bedrock并向第三方身份提供商开放
苹果13英寸iPad Pro Magic键盘键盘亚马逊历史低价,直降25%
WhatsApp iOS版Liquid Glass界面设计正式向更多用户推送
OpenAI为ChatGPT Pro推出个人财务管理新功能
赛格威全新Xaber 300电动越野摩托车正式开售,最高时速达96公里
