
我们开源啦!一键部署免费使用!Kubernetes上直接运行大数据平台!
智领云自主研发的首个完全基于Kubernetes的容器化大数据平台
Kubernetes Data Platform (简称KDP)
开源啦!
开发者只要准备好命令行工具,一键部署
Hadoop,Hive,Spark,Kafka, Flink, MinIO ...
就可以创建以前要花几十万甚至几百万才可以买到的大数据平台
无需再花大量的时间和经费去做重复的研发
高度集成,单机即可体验大数据平台
在高级安装模式下
用户可在现有的K8s集群上集成运行大数据组件
不用额外单独建设大数据集群
项目地址:
https://github.com/linktimecloud/kubernetes-data-platform
辛辛苦苦研究出来的成果,为什么要开源?
这波格局开大,老板有话说
问题1:我们为什么要开源?
我们的产品一直是基于大数据开源生态体系建设的。之前就一直有开源回馈社区的计划,但是因为之前Kubernetes对于大数据组件的支持还不够成熟,我们也一直在迭代与Kubernetes的适配。现在我们的企业版已经在很多头部客户落地并且在生产环境下高效运行,觉得这个版本已经可以达到大部分生产级项目的需求,集成度以及可用性是能够帮到有类似需求的用户的,希望这次开源能够降低在Kubernetes上集成大数据组件的门槛,让更多Kuberenetes和big data社区的同行们可以使用。
问题2:开源版本的KDP,能干啥?
KDP可以很方便的在Kubenetes上安装和管理常用的大数据组件,Hadoop,Hive,Spark,Kafka, Flink, MinIO 等等,不需要自己一个一个去适配,可以直接开始使用。然后KDP也提供集成的运维管理界面,用户可以从界面管理所有组件的安装配置,运行状况,资源使用情况,修改配置。而且KDP会将一个大数据组件的所有负载(容器,pod)作为一个整体管理,用户不需要在Kubernetes的控制平面上去管理单独的负载。
问题3:最大的亮点是?
只要你已经在使用Kubernetes,那么在现有集群上十几分钟就可以启动一个完整的大数据集群,马上开始使用,极大的降低了大数据平台的使用门槛。因为我们这个流程是高度集成的,整个安装过程在一个单机环境下也都能启动(例如使用单机kind虚拟集群都可以),所以在测试和实验环境下都可以高效使用。当然,启动之后Day 2的很多好处,例如资源的高效利用和集成的运维管理,也是KDP提供的重要功能。
KDP,即在Kubernetes上使用原生的分布式功能搭建及管理大数据平台。
将多套大数据组件集成在Kubernetes之上,同时提供一个整体的管理及运维工具体系,形成一个完全基于Kubernetes的大数据平台。企业级KDP更是支持在同一个Kubernetes集群中同时运行多个大数据平台以及多租户管理的能力,充分发挥Kubernetes云原生体系的优势。
KDP,通过对开源大数据组件的扩展和集成,实现了传统大数据平台到K8s大数据平台的平稳迁移。
作为市场上首个可完全在Kubernetes上部署的容器化云原生大数据平台,智领云自主研发的KDP,深度整合云原生架构优势,将大数据组件、数据应用及资源调度混排,纳入Kubernetes管理体系,从而带你真正玩转云原生!
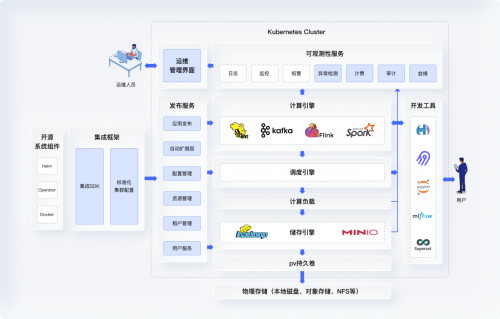
总体框架
简单来讲,KDP可以允许客户在Kubernetes上运行它所有的大数据组件,并把它们作为一个整体管理起来。
在Kubernetes上运行大数据平台有三个好处:
第一,更高效的大数据组件集成:KDP提供标准化自动化的大数据组件部署和配置,极大地缩短了大数据项目开发和上线时间;
第二,更高效的大数据集群运管:KDP通过大数据组件与K8s的集成,在K8s之上搭建了一个大数据组件管理抽象层,标准化大数据组件生命周期管理,并提供UI界面进一步提升了部署、升级等操作的效率;
第三,更高的集群资源利用率:利用K8s的资源管理和配额机制,与其它系统共享K8s资源池,精细化资源管理,对比传统大数据平台约30%左右的资源利用率,KDP可大幅提升至60%以上。
社区
我们期待您的贡献和建议!最简单的贡献方式是参与Github议题/讨论的讨论。 如果您有任何问题,请与我们联系,我们将确保尽快为您解答。
微信群:添加小助手微信拉您进入交流群
钉钉群:搜索公开群组号 82250000662
贡献
参考开发者指南,了解如何开发及贡献 KDP。
https://linktimecloud.github.io/kubernetes-data-platform/docs/zh/developer-guide/developer-guide.html
好文章,需要你的鼓励


CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
很多人担心被AI取代,陷入无意义感。按照杨元庆的思路,其实无论是模型的打造者,还是模型的使用者,都不该把AI放在人的对立面。

MIT递归语言模型:突破AI上下文限制的新方法
MIT研究团队提出递归语言模型(RLM),通过将长文本存储在外部编程环境中,让AI能够编写代码来探索和分解文本,并递归调用自身处理子任务。该方法成功处理了比传统模型大两个数量级的文本长度,在多项长文本任务上显著优于现有方法,同时保持了相当的成本效率,为AI处理超长文本提供了全新解决方案。

Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
谷歌宣布对Gmail进行重大升级,全面集成Gemini AI功能,将其转变为"个人主动式收件箱助手"。新功能包括AI收件箱视图,可按优先级自动分组邮件;"帮我快速了解"功能提供邮件活动摘要;扩展"帮我写邮件"工具至所有用户;支持复杂问题查询如"我的航班何时降落"。部分功能免费提供,高级功能需付费订阅。谷歌强调用户数据安全,邮件内容不会用于训练公共AI模型。

华为研究团队突破代码修复瓶颈,8B模型击败32B巨型对手!
华为研究团队推出SWE-Lego框架,通过混合数据集、改进监督学习和测试时扩展三大创新,让8B参数AI模型在代码自动修复任务上击败32B对手。该系统在SWE-bench Verified测试中达到42.2%成功率,加上扩展技术后提升至49.6%,证明了精巧方法设计胜过简单规模扩展的技术理念。
2024
04/26
09:58
分享
点赞

联想集团混合式AI实践获权威肯定,CES期间获评“全球科技引领企业”
CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
CES 2026 | 重大更新:NVIDIA DGX Spark开启“云边端”模式
Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
研究发现商业AI模型可完整还原《哈利·波特》原著内容
Razer在2026年CES展会推出全息AI伴侣项目
CES 2026:英伟达新架构亮相,AMD发布新芯片,Razer推出AI奇异产品
通过舞蹈认识LimX Dynamics的人形机器人Oli
谷歌为Gmail搜索引入AI概览功能并推出实验性AI智能收件箱
DuRoBo Krono:搭载AI助手的智能手机尺寸电子阅读器
OpenAI推出ChatGPT Health医疗问答功能
Anthropic寻求3500亿美元估值融资100亿美元
