
NVIDIA Jetson Nano 2GB 系列文章(32):架构说明与deepstream-test范例
大部分DeepStream应用演示,都会使用SDK提供的deepstream-app这个非常强大的体验工具,这是从3.x版本就已经开发好的演示应用,只要挑选samples下面的config/deepstream-app里面十多个配置文件,花个十几分钟时间进行小幅度修改,然后用“-c”指定配置文件,就能实现非常多的强大功能,可以执行非常专业的(多屏)输出显示,而且执行性能非常好。
如果您执行过前一篇文章的实验,就能体验到DeepStream执行多检测器(detector)加成识别的应用,在Jetson Nano 2GB上居然能得到4路视频都在20+FPS的性能,如果刨去安装环境的时间,从头到尾大概十几分钟时间就能完成。
这种情况让众多专注在视频分析软件开发的资深工程师,承受了前所未有的巨大压力,因为过去可能需要5位以上熟练的工程师、花费至少4~6个月时间开发的功能,如今一个初学者就能在DeepStream上,仅用几十分钟就作出专业的效果,这就是“善用工具”所带来的威力。
正因为deepstream-app这个演示工具太过强大,几乎将DeepStream绝大部分特色功能都涵盖进去,导致有不少人误以为deepstream-app就是整套DeepStream开发包,只要把设定文件里面的“群(group)参数”搞通了,就能驾驭这套视频分析工具,然后走偏路子。
当然,能将这些设定值研究透彻,也能用deepstream-app去实现非常多的强大应用,已经是非常厉害的,但这并不能完全发挥DeepStream的全部功能,或者开发一些特殊功能的应用。
NVIDIA在github.com/NVIDIA-AI-IOT里面有非常多DeepStream的开源项目,就并非使用deepstream-app透过修改参数去完成的,而是用全新的代码去开发,例如“
deepstream-occupancy-analytics人流分析”、“deepstream_lpr_app车牌识别”、“redaction_with_deepstream视频编辑”、“deepstream_pose_estimation姿势识别”、“Deepstream-Dewarper-App 360度镜头还原”等等,都是直接用DeepStream的插件与API接口直接开发的项目。
Gstreamer的基本组成元件
事实上DeepStream是基于Gstreamer框架所搭建的,因此应用程序就是由一连串的GStreamer管道(pipeline)所组成,下面就是最基本的管道示意图:
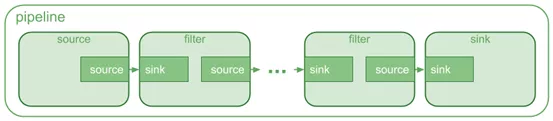
从视频输入流到一系列用于处理流的元素或插件以及深入的输出流组成,每个插件都有一个定义的输入(名为sink)和定义的输出(名为source)。在管道中,一个插件的源衬垫(source pad)连接到下一个插件的接收器板(sink pad),源包括从处理过程中提取的信息、元数据,这些信息可用于视频注释和关于输入流的其他细节。
典型的应用工作流包括“输入源处理”、“计算处理”、“汇总输出”三大步骤,DeepStream也不例外,下图就是这个开发工具的标准工作流:
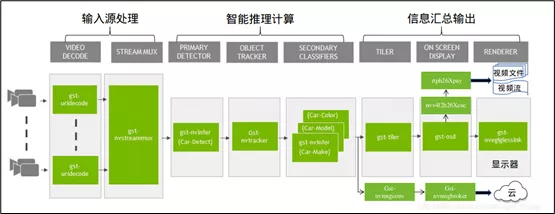
Gstreamer框架在输入与输出部分,原本就提供非常丰富的插件,因此DeepStream除了需要调用NVIDIA并行计算能力或硬件资源的部分,包括视频颜色空间转换、图像处理(放大/缩小/旋转)、streammux/streamdemux多图像组合/分解处理、图像合成渲染、以及Jetson设备上的H254/H265/JPEG硬件编解码器、CSI摄像头调用的ISP图像信号处理器等,其他都直接使用Gstreamer的开源插件。
以下列出输入/输出部分相关的插件名称与简单说明:
GStream的开源插件
- GstFileSrc:从文件中读取数据:视频数据或图像。
- Gst-v4l2src:从v4l2设备(例如USB摄像头或视频采集卡)捕获视频流。
- GstURIdecodebin:将数据从URI解码到原始媒体中。它选择可以处理给定“ uri”方案的源元素,并将其连接到解码器。
- GstCapsFilter:不修改数据的情况下限制数据格式。
- GstH26xParser:其中x=4或5,读取h264或h265视频进行解析。
- GstRtpH26xPay:其中X=4或5,将h26X编码的有效负载转换为RTP数据包.
- GstFileSink:传入数据写入本地文件系统中的文件。
- GstUPDSink:将UDP数据包发送到网络,这个与RTP有效负载(rtph26Xpay)配对时,它可以实现RTP流。
NVIDIA提供的插件:
请参考DeepStream开发手册的DS_plugins_intro.html
1. 输入输出相关:
- Gst-nvArgusCameraSrc:提供使用Argus API控制ISP属性的选项。
- Gst-nvStreamMux:当有多个输入源打时候,就需要将多个图像帧进行批次处理,然后再一并传送给推理计算插件。DeepStream使用可扩展的元数据(metadata)标准结构,基本元数据结构NvDsBatchMeta从批次级(batch)元数据开始,该元数据是在所需的Gst nvstreammux插件中创建的。辅助元数据结构包含框架、对象、分类器和标签数据。DeepStream还提供了一种在批处理、帧或对象级别添加用户特定元数据的机制。
- Gst-nvStreamDemux:将批处理的图像帧,分解为多路的单独缓冲区。
- Gst-nvDSOsd:绘制边界框,文本和关注区域(ROI)多边形。
- Gst-nvVideoConvert:执行视频颜色格式转换,接受NVMM内存以及RAW(使用calloc()或分配的内存malloc()),并在输出处提供NVMM或RAW内存。
- Gst-nvVideo4Linux2:这是DeepStream 5.0增加的插件,NVIDIA将Gstreamer的开源Gst-v4l2解码插件进行扩展,通过Jetson和DGPU的libv4l2插件接口,以支持设备上提供的硬件加速编解码器的调用:解码器(decoder):支持H.264,H.265,JPEG和MJPEG格式
编码器(Encoder):接受I420格式RAW数据,使用NVENC对RAW输入进行编码,输出采用基本比特流支持的格式。 - Gst-nvJpegDec:解压缩图片的编解码器。
2. 智能推理计算:这部分全都由NVIDIA提供专属的插件,最重要的是推理(inferece)与追踪(track)两大功能,然后再添加智能统计分析插件,主要如下:
- Gst-nvinfer:使用TensorRT对输入数据进行推断,这是整个DeepStream执行推理计算的核心插件,上面接受批处理的NV12 / RGBA缓冲区。NvDsBatchMeta结构必须已经附加到Gst缓冲区。低级库(libnvds_infer)可对尺寸为“网络高度”和“网络宽度”的INT8 RGB,BGR或GREY数据进行操作。Gst-nvinfer插件根据网络要求在输入帧上执行转换(格式转换和缩放),并将转换后的数据传递到低级库。低级库对转换后的帧进行预处理(执行归一化和均值减法),并生成最终的float RGB / BGR / GRAY平面数据,该数据将传递到TensorRT引擎进行推理。低级库生成的输出类型取决于网络类型
- Gst-nvinferserver:使用NGC上的Triton Inference Server对输入数据进行推断,插件使用对应于NGC容器20.03的NVIDIA®Triton Inference Server(以前称为TensorRT Inference Server)1.12.0版对输入数据进行推断。请参阅 https://docs.nvidia.com/cn/deeplearning/triton-inference-server/user-guide/docs/index.html
- Gst-nvtracker:跟踪帧之间的对象,并为每个新对象提供唯一的ID。该插件跟踪检测到的对象,并为每个新对象提供唯一的ID。该插件将低级跟踪器库适应管道。它支持实现底层API的任何底层库,包括三个参考实现NvDCF,KLT和IOU跟踪器。作为此API的一部分,该插件会查询低级库以获取有关输入格式和内存类型的功能和要求。然后,它将输入缓冲区转换为低级库请求的格式。
- Gst-nvdsanalytics:这个插件对nvinfer(主检测器)和nvtracker附加的元数据执行分析。分析是指感兴趣区域(ROI)过滤、过度拥挤检测、方向检测和线路交叉。插件在批处理模式下运行,它独立地处理每个流的上下文。基于ROI的分析工作在主要探测器输出上,但是方向检测和线交叉需要跟踪器id,因为之前的历史/状态都需要进行分析。分析规则的配置是使用配置文件实现的。
3. 智能推理计算:为了配合AIOT的需求,NVIDIA也提供下面两个插件,配合将统计分析过的特定信息,透过相关的通信协议上传到指定的网络位置:
- Gst-nvmsgconv:将DeepStream完整模式所支持打对象检测、分析模块、事件、位置和传感器详细语义等任何有获取对象的信息,传输到消息代理(message broker)去。
- Gst-nvmsgbroker:此使用指定的通信协议向服务器发送有效负载消息。
4. 其他:最后还有两个特定应用的插件,一个是配合360度鱼眼监控摄像头,将画面还原成为平面图像的插件,另一个是针对光流计算的应将加速器:
- Gst-nvdevarper:使摄像机输入分离,接受gpu-id和config-file作为属性,根据选定的曲面配置,它最多可以生成四个变形曲面,这个功能很有效地应用在360度摄像头的图像还原应用。
- Gst-nvof:这个计算光流的硬件加速器目前只有在Jetson Xavier上才有支持。
这里可以看到在“输入/输出”部分的插件数量是最多的,如果参考下面示意图,就可以更清楚的确在“输入/输出”阶段的数据处理步骤是比较繁琐的,在程式之中绝大部分的代码也都是在这两方面的处理,特别在“格式转换”的部分。
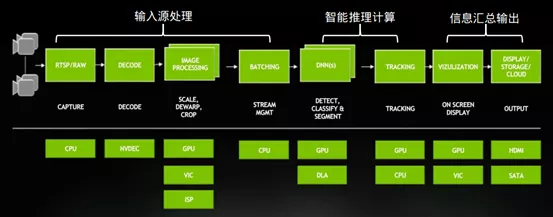
至于智能推理计算的部分,主要就是将深度学习的网络模型转换成TensorRT加速引擎,然后进行推理计算,步骤是单纯的但计算量是最大的。
deepstream-app这个范例为了展现完整的功能,于是使用deepstream_app.c、deepstream_app_main.c与
deepstream_app_config_parser.c这三支程式,总代码量超过2,200行,反而不适合入门开发人员去修改成自己想要的专属应用。当然不是说做不到,而是你必须花费更多时间去解读的所有内容。
而DeepStream开发套件的<主目录>/sources/apps/sample_apps里提供大约20个C/C++范例代码,除了deepstream-appa是通用范例之外,其他的都是特定应用的基础代码,特别是deepstream-testN系列范例是比较合适入门学习。
接下去就简单执行test1与test2两个范例,让大家简单体验一下这些功能:
Deepstream-test1实验
对刚入门的朋友来说,建议从“deepstream-test”系列范例入手比较合适,其中deepstream-test1是最基础的代码,这个300+行的程式中在每个阶段都使用最基本的插件,下面简单列出处理重点以及插件流内容:
- 编程语言:C/C++
- 代码量:326行(含注解)
- 输入源:单个H264/H265视频文件
- 智能推理:单个的4类别(car, person, bicycle, roadsign)检测器
- 显示输出:显示器
- 管道流:filesrc -> h264parse -> nvv4l2decoder -> nvstreammux -> nvinfer (primary detector) -> nvvideoconvert -> nvdsosd -> nvegltransform -> nveglglessink
DeepStrem安装过程都把这些范例编译好,并且都将执行文件移到 /usr/bin 目录下,表示功能上我们可以在任何地方去调用,不过代码中已经将配置文件指定为dstest1_pgie_config.txt,因此现在得先到这个测试目录下进行。请执行以下指令:

这个设定文件使用一个“4分类(Car, Bicyce, Person, Raodsign)”检测器,不过视频中只有“Person”内容,您可以试试其他视频作为输入。

Deepstream-test2实验
接着看一下deepstream-test2的范例,这是基于test1的基础上去添加“多级检测器”的功能,由于这个功能与DeepStream的追踪功能相捆绑,因此也许一并启动。
- 编程语言:C/C++
- 代码量:506行(含注解)
- 输入源:单个H264/H265视频文件
- 智能推理:单个的4类别(car, person, bicycle, roadsign)主检测器,加上3个基于“Car”类别的次级检测器,包括颜色、品牌、车型等等,这里还必须打开“追踪器(tracker)”的功能
- 显示输出:显示器
- 插件流:filesrc -> h264parse -> nvv4l2decoder -> nvstreammux -> nvinfer (primary detector) -> nvtracker -> nvinfer(secondary classifier) -> nvvideoconvert -> nvdsosd -> nvegltransform -> nveglglessink
执行以下指令,看看执行结果与test1有什么不同?

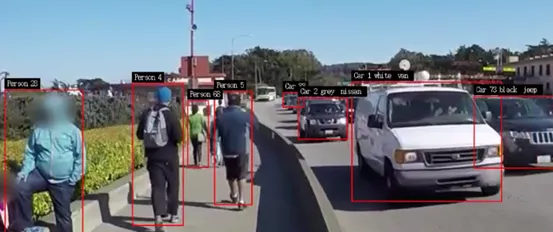
这里明显看到test2不仅能为每个检测到的物体标上编号,这就是“追踪”的功能,在“car”物体上,还有“颜色”、“品牌”、“车型”等信息。
结语
使用deepstream-app可以让我们轻松透过修改配置文件去快速执行DeepStream一些亮眼的演示,但真正要进入到实际应用时,就存在不少deepstream-app所不能完成的功能,必须仰赖其他范例代码的协助。
例如“redaction_with_deepstream”这个视频实时编辑的开源项目,在时下“隐私权”高涨的时代中非常重要,这个应用在视频中检测到人脸或车牌之后,将这些牵涉到个人隐私的信息图块进行“遮盖”动作,虽然难度并不高,但在目前小视频充斥的潮流中就显得十分重要。而“遮盖”功能在deepstream-app并没有提供,要进行改写的困难度不小,因此这个项目就基于deepstream-test1这个范例进行改写而成。
另外一个“deepstream_lpr_app”车牌识别应用,是由一个Car主检测器(primary detector),配合Plate次检测器(secondary detector)与字符抽离的分类器(classifier),最终将车牌内容识别出来(如下图),这个项目就以deepstream_test2_app.c的基础进行开发。

这两个项目将在下一篇文章中进一步说明,其他还有“姿势识别”、“360度视角还原”、“人流分析”等项目,也都是基于deepstream-test范例代码所改写的,因此学习用这些范例去开发自己的应用,才是长期的正道,也是本系列文章后面所要说明的重点,包括DeepStream的Python范例等等。
来源:至顶网CIO与CTO频道
好文章,需要你的鼓励



印度理工学院突破性发现:大脑学习规律启发的全新AI图像生成技术
印度理工学院研究团队从大脑神经科学的戴尔定律出发,开发了基于几何布朗运动的全新AI图像生成技术。该方法使用乘性更新规则替代传统加性方法,使AI训练过程更符合生物学习原理,权重分布呈现对数正态特征。研究团队创建了乘性分数匹配理论框架,在标准数据集上验证了方法的有效性,为生物学启发的AI技术发展开辟了新方向。

英伟达与诺基亚联手开创AI驱动6G通信平台
英伟达和诺基亚宣布战略合作,将英伟达AI驱动的无线接入网产品集成到诺基亚RAN产品组合中,助力运营商在英伟达平台上部署AI原生5G Advanced和6G网络。双方将推出AI-RAN系统,提升网络性能和效率,为生成式AI和智能体AI应用提供无缝体验。英伟达将投资10亿美元并推出6G就绪的ARC-Pro计算平台,试验预计2026年开始。

Sony AI推出SoundReactor:让AI实时从画面生成身临其境的立体声音效
Sony AI开发出SoundReactor框架,首次实现逐帧在线视频转音频生成,无需预知未来画面即可实时生成高质量立体声音效。该技术采用因果解码器和扩散头设计,在游戏视频测试中表现出色,延迟仅26.3毫秒,为实时内容创作、游戏世界生成和互动应用开辟新可能。
2021
09/14
17:40
分享
点赞

张凌赫空降现场!天禧个人超级智能体3.5与联想moto X70 Air AI手机正式发布
张凌赫同款AI眼镜震撼亮相:联想AI眼镜M1售价998元起,V1开启预售
联想发布天禧个人超级智能体3.5版本:AI看世界、AI翻译海量AI热门应用全面升级
当轻薄与智能融入日常,联想正在讲述新的终端故事
联想moto X70 Air正式发布:以极致轻薄重塑轻薄AI手机新体验
科世达、德华安顾人寿、宝洁和汇丰银行荣获2025红帽亚太创新奖
联想集团荣获拉姆·查兰管理实践奖 以AI原生组织“破局”开源降本提效
英伟达与诺基亚联手开创AI驱动6G通信平台
智能座舱的“理想”样本背后,为什么需要一朵AI云?
ChatGPT不是万能的:11个不应该依赖AI的重要领域
核能能否成为推动全球AI发展的能源伙伴?
Blue Energy计划建设燃气转核能数据中心电厂
