
南京证券数智化客户营销服务运营展业平台
证券行业IT投入连续两年增幅超过20%,多家券商每年投入超过10亿元。在金融科技投入成本有限的情况下,如何保持数字化转型发展不掉队,是大多数中小券商无法回避的问题。同时,证券行业数字化转型复合型人才的供给不足,造成数据技术应用难以保持同步,实际业务与数据技术应用覆盖范围之间长期存在偏差。
基于行业现状,南京证券制定以聚焦匹配、业务融合为原则,"一个战略,三大体系,五项能力”的发展路径,建设以客户服务为核心,提升业务能力与工作效率、降低综合风险与运营成本为目标的公司数字化发展战略,自主研发打造的数智化客户营销服务运营展业平台(以下简称"展业平台”),平台依托云原生架构进行一体化敏捷开发,提升交付速度,降低试错成本,高效响应需求,提高用户体验,全方位赋能员工展业和南京证券财富管理转型。
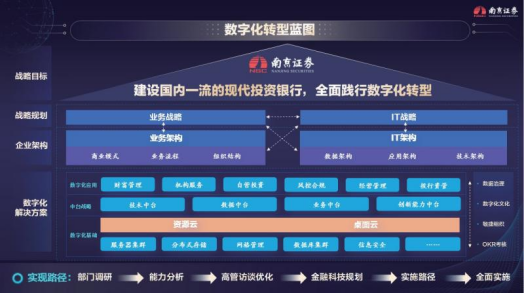
图:数字化转型蓝图
技术架构方面,展业平台依托技术中台,实现应用的快速迭代开发、监控、治理、渠道接入与访问控制,架构出“大中台,小应用“模式,根据不同业务场景实现业务应用,下沉技术组件和公共模块,做到灵活支持业务的创新迭代,快速响应用户需求。同时,基于国产
大数据技术建设大数据平台,结合Hive, Kafka, HBase, Flink等技术组件,以及元数据管
理、数据质量管理、血缘分析等数据管控工具,实现数据的集中存储与计算,消除了业务和系统之间的分散隔阂,大幅提升了数据质量,实现了高可靠、高可用,并在技术中台和数据中台的基础上,建设数智化客户营销服务运营展业平台,搭建了客户中心、画像中心、产品中心、运营中心、内容中心等业务组件。
业务模式方面,展业平台目前用户规模1000余人,覆盖证券行业相关的多业务条线,比如经纪业务、零售业务、机构业务、信用业务等。平台通过客户经理、投资顾问等一线员工服务了南京证券的大晕客户,提升南京证券金融服务的能力水平以及客户服务体验和满意度。作为南京证券数字化转型的重要组成部分,对内提升运营效率,对外提升客户体验,赋能一线分支机构,扩大服务半径、提升服务效能,实现队伍综合业绩与业务收入的突破性增长。
展业平台成为南京证券经纪业务数字化转型的配套基础,实现了对客户全生命周期的数
细化管理,以客户为中心,利用数据挖掘和算法优化等方法,建立客户全生命周期运营体系,实现超百万客户的标签画像体系精准分析与精细化管理。
为客户经理在获客、服务、提醒、转化、营销、挽留、关怀等提供一揽子策略支持。平台融合汇聚各业务系统,打通系统数据隔闵,实现业务的便捷管理与精准统计。展业平台的 “经管佣金设置和信用佣金复核”功能在原有基础上提升信息处理时效40%,整体工作效率提升30%, “客户资料预审”为公司节约后期管理维护费用约200万元,实现了降本增效。
展业平台的建设,使得公司在企业级应用APP相关平台的细分市场上份额能够大幅提升,从而对接更多交易合作伙伴,日新增运营超过原有承载能力的多个产品,处理数据量远超同类平台。同时通过该项目的自主研发,进一步提升了相关技术人员的基础研究能力,促进产研技术的进步,有效带来丰富的研发项目管理经验以及研发知识的累积,为突破技术瓶颈以及未来的研发活动的开展夯实牢固的基础。
展业平台的建设面向大型证券企业数字化转型升级的重大战略需求,针对满足严格监管环境下,研发企业级应用APP提高企业开发和建设能力,在追求不同场景多标准适用的同时,实现数据处理的伸缩扩展稳定性达到最高水平,为金融行业客户运营提供了成功的实践经验和经典案例,推动了细分领域内的技术革新与多样化。
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2023
12/19
18:43
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
