
Gartner:在中国投资进行元数据驱动数据编织设计的三大理由
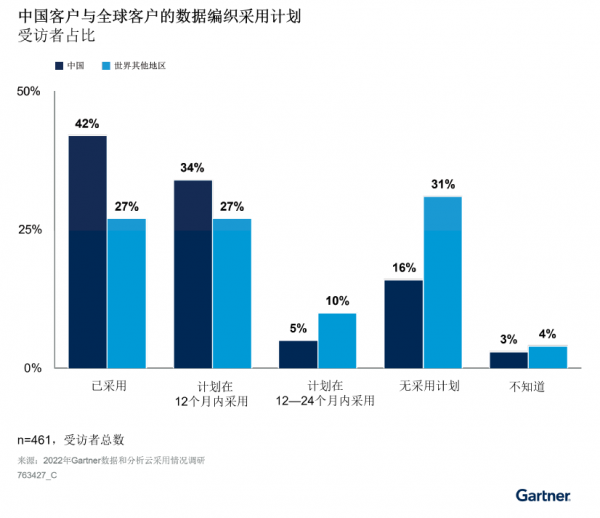
数据编织是一种新兴的数据管理设计,在中国保持了较高的市场吸引力。2022年Gartner数据和分析云采用调研显示,尽管受访者对“数据编织”一词的定义不尽相同,但42%的中国用户表示已采用这一技术,另有34%的受访者计划在未来12个月内采用这项技术。这两个选项的受访者占比都超过了全球水平(见图1)。
图1:中国客户与全球客户的数据编织采用计划
数据分析和人工智能(AI)技术及其在垂直行业用例的爆炸式增长,使企业数据基础设施变得日益复杂和难以维护。经济和地缘政治不确定性导致数据监管环境难以预测,进一步提高了管理难度。如果企业无法实施由主动元数据驱动的数据编织来提升数据和分析(D&A)弹性和敏捷性,D&A系统的维护成本将超过其创造的价值。
千变万化的宏观环境导致了数据管理规范的不确定性
过去两年,中国政府发布了多项国家原则,如《数据二十条》和《数字经济发展十四五规划》,以促进数据、分析和AI在经济中的应用。与此同时,新的数据分析和AI用例(物联网[IOT]、数字孪生、元宇宙、生成式AI等)不断涌现,使中国企业机构进一步推动数据分析和AI的普及。
另一方面,主要由地缘政治紧张局势驱动的数据安全原则和自给自足要求,也在迫使企业更谨慎、更合规地使用数据。
为同时满足上述两个看上去对立的需求,数据和分析能力的升级路线图和优先任务变得难以预测。同时,由于缺乏对当前数据和分析平台使用情况的持续监控和分析,企业无法主动识别潜在的分析需求和问题,导致大部分数据管理任务很被动。数据编织中的主动元数据管理,可以帮助企业机构以主动和自主的方式识别这些需求和问题。
更加复杂和去中心化的D&A架构
由于境内外的D&A供应商生态系统完全不同,数据安全和跨境数据传输法规日益明确,在中国境内和境外同时开展业务的企业(例如在中国开展业务的跨国企业,以及正在海外开展业务的中国企业)必须构建两组不同的D&A架构,甚至是不同的IT架构。对于仅在中国境内开展业务的企业机构来说,云迁移和技术自给自足计划的开展,会使其D&A架构长期处于转型中的状态。
出于上述原因,中国企业机构的D&A架构与全球同行相比,会具有更强的去中心化属性和复杂性。这将导致IT运营成本大幅增加,流程也会变得更为复杂。
分析对比数据的设计期望与实际体验之间的差距,可以更有效地完成上述大部分任务。数据编织中的主动元数据管理,通过比较设计时元数据和运行时元数据来帮助企业机构分析数据的设计期望与实际体验。这将使企业机构的系统、数据和数据管道在资源效率、性能、安全性、合规性和可用性方面始终处于“自动化可观测”状态。
跨部门沟通障碍
技术和业务团队之间的沟通障碍,仍然是中国企业机构快速、可持续地利用数据创造业务价值的一个主要障碍。2022年,Gartner收到了大量中国客户关于D&A项目跨部门沟通的问询,包括如何更好地与业务利益相关者对齐数据业务语义,以及如何使数据团队更快地做出响应。这些问题大多关乎数据定义与其真实运营体验之间的偏差,即“语义漂移”。在大型企业机构中,这个问题更严重,会拖累或阻碍数据和分析项目。
主动元数据管理通过对数据工程师和数据消费者内容的持续分析,生成大量洞察,包括:
- 特定用例中使用的源数据语义是否发生了变化
- 数据使用过程中是否存在安全或隐私问题
数据管道中的业务逻辑是否需要更新,以纠正语义漂移导致的数据质量问题
好文章,需要你的鼓励


Siri AI、ChatGPT、Claude真实横评,谁才是最强AI助手?
海外博主做了一次 Siri AI、ChatGPT、Claude 横评。看完之后我最大的感受是,AI 助手的竞争已经不只是模型能力,而是谁离用户更近。

南京大学团队打造的“轻量AI视频助理“:不用反复推理,一眼就能看懂你的过去
南京大学提出Light-Omni框架,通过全局状态与潜在状态双机制,让AI视频助理无需反复推理即可实现精准记忆检索,速度提升逾12倍,准确率同步提高。

Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber年度失物报告首次纳入无人驾驶出租车数据。过去一年,乘客在Uber平台的机器人出租车中遗留了数千件物品,包括手机、钥匙、钱包等常见物品,以及假牙、15磅溜溜球等奇特物件。乘客可通过App联系客服找回失物,支付15美元即可享受同城配送,或前往车辆停放站自取。Uber表示,将依托现有运营体系为自动驾驶业务提供全面支持,计划2025年底前在全球15座城市开通无人驾驶打车服务。

当AI学生卡在难题前:LinkedIn等机构如何让AI通过“偷师学艺“突破学习瓶颈
TREK方法通过引入外部验证解法对AI进行短期校准,解决了GRPO训练在困难题目上因无法探索正确解法区域而陷入瓶颈的问题,在数学推理和智能体任务上均取得明显提升。
2023
07/17
13:03
分享
点赞

Siri AI、ChatGPT、Claude真实横评,谁才是最强AI助手?
Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber、Wayve与Waymo的伦敦无人驾驶出租车大战即将开启
Mobileye计划2027年在美国推出自动驾驶出租车服务
Waymo召回近4000辆无人出租车,原因是其进入高速公路施工区域
特斯拉在奥斯汀开始测试无方向盘无踏板Cybercab量产版
图灵奖得主Patterson:摩尔定律的真相,CPU、GPU、TPU的诞生与分工
Omdia报告:Dell PowerProtect助力企业三年期网络弹性TCO最高降低61%
“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
