
Gartner: 充分利用中国数据库管理系统的发展,满足企业机构不断演进的需求
中国独特的商业环境和对技术自主可控的强烈需求,带来了中国数据库管理系统(以下简称为“数据库”)市场的繁荣和多样性。
虽然中国的数据库厂商在许多方面,如云生态系统的建立和云财务治理等方面,仍然落后于以亚马逊云服务、谷歌、微软和甲骨文为代表的外国厂商,但在中国独特的业务环境下,本土厂商的产品演进十分迅速,且产生了差异化优势,因此在一些应用场景中具备竞争力。
中国本土数据库具有以下几个主要技术特征。
分布式事务型数据库的采用率正在上升
分布式事务型数据库已经成为企业机构支撑核心业务系统的现实选择,它们在中国的使用增长速度要快于世界其他地区。
Gartner对分布式事务型数据库(DTDB)的定义是:可在任何分布式数据库实例节点上执行事务的数据库。这项技术的特点在于,在接受地理上分散分布的节点写入的同时,保持数据完整性和一致性,且性能合格。
在中国的移动互联网蓬勃发展过程中,实现业务敏捷性的主要阻碍是数据工作负载规模化的速度和成本。工作负载的需求增长,不仅使业务性能降低,而且,如果企业机构决定扩充资源,则还会带来额外的高昂硬件成本。使用DTDB,不仅可以支持应用的高并发和高数据吞吐量,还可以减少对由外国厂商提供的大型机硬件的依赖——这也与国家“自主可控”战略举措的目标相符。
今天,随着诸如分布式一致性共识算法和并发控制技术等大量技术创新的出现,DTDB可确保在不牺牲过多可扩展性和性能的情况下,实现数据的高度一致性。与此同时,DTDB与公有云的兼容性也正在持续提升;因此,在资源使用不断变化且难以预测的环境中,云部署将成为理想选择。
数据密集型应用场景需要超高性能数据库
在过去的三年间,新冠疫情进一步加快了网上购物、线上出行和在线教育等数字化应用场景的普及。作为所有应用的核心数据基础设施,数据库需要提供更为强大的性能,以支持全部数据密集型应用场景。
一些典型的超高性能应用场景包括:
- 全国性社会活动,例如国家人口普查,需要能够支持每秒100万至200万个查询,以及每秒处理10万至50万件事务。
- 大型活动的转播,例如奥运会或春晚,通常需要能够支持1000万到2000万本土观众同时在线观看。
- 许多中国超大规模企业的数据存储总量已经达到10PB至100PB,日增数据量超过10TB。
- 网上购物节活动,例如“双十一”和“618”购物节,都会产生极高的事务数量。
- 中国庞大的互联网用户规模,会使一些常规的网络活动,例如网上订餐、网约车、在线教育等的工作负载成倍加大,导致高峰时段事务处理的工作负载尤为繁重。在高峰时段,事务处理工作负载有时比非高峰时段高100倍。
中国的数据库厂商都在不断演进各类技术,以支持数据密集型应用场景。这些技术包括大规模并行处理(MPP)、分布式事务、内存数据处理和行列混合处理等。近年来,一批初创厂商开始快速获得关注。这些厂商将超高性能作为其核心竞争差异化优势,丰富了企业机构的选择面,但也使得市场状况变得更加复杂。
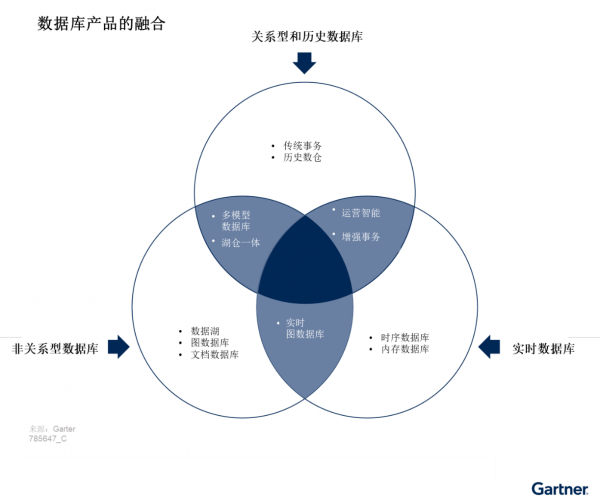
各类专业化的数据库正不断融合,成为集成各类功能的统一型数据库服务
在过去的15年间,中国企业机构采用了各类专业化的数据库,用于各类不同类型数据库的操作和分析。比如:
- 非关系型数据库,例如图数据库和文档数据库,可用于存储和处理图数据和文档数据,以支持机器学习和图分析。
- 时序数据库和内存数据库可用于支持时间敏感性应用场景,例如流分析和决策智能。
由于每个应用场景均有海量的数据库产品可供选择,相应地,连接这些数据库的数据管道也越建越多,导致企业机构数据和分析架构的复杂性大大增加。这一复杂性也导致了运营效率低下,获取洞察的时间被延长。为解决这一问题,中国和全球的数据库厂商都在采取行动,扩大各自产品的应用场景覆盖范围,形成了数据库功能融合的局面。这一融合趋势在多模型数据库中得以体现。这类数据库可以通过多个应用编程接口(API)来支持多种存储和持久保存数据的方式。
如图1所示,Gartner从数据类型和时间敏感性几个方面对这一趋势进行了观察研究。
图1:数据库产品的融合
好文章,需要你的鼓励


一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

Sakana AI与毕马威联手打造“咖啡经济沙盘“:当AI商人学会讨价还价,它们会做出什么选择?
CoffeeBench是Sakana AI与毕马威联合构建的多智能体经济基准测试,让六个AI企业在90天咖啡供应链模拟中自主经营,评估大语言模型的长期商业决策能力。

借鉴生态学模型评估AI风险的新方法
本文提出一种评估人工智能风险的新方法,借鉴生态学与演化论视角,从理论生态模型中推导出三项风险指标,涵盖种群模型与生态系统模型。研究旨在为AI治理策略提供量化工具,并对分析局限性及政策改进方向进行了深入探讨,为构建更科学的AI风险评估体系提供参考框架。

牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

