
看烽火HA-Stack如何解码政务云智能化
近年来,随着云计算、大数据、物联网、人工智能等热点技术的逐步落地,人们已经切身感受到新一轮科技革命带来的日新月异变化,利用新ICT 技术在产品服务、业务模式、组织架构、IT流程方面的创新应用已经成为数字化时代的必然选择,智慧城市中包含的智慧政务、智慧交通、智慧教育、智慧医疗等已经成为城市建设主流的发展趋势。
在8月11日的《智享云未来 2017云计算技术与应用高峰论坛》中,烽火云计算资深产品专家赵锐为大家带来了《政务云智能化之路》的主题演讲。作为中国智慧城市建设的领导者,烽火时刻关注政务领域信息化建设需求,积累了大量的行业经验与技术优势。赵锐在演讲中提到,在湖北省楚天云的建设中,烽火自研的FitOS虚拟机高可用解决方案(HA-Stack)为保证关键业务连续性提供了重要技术支撑。另外,烽火的HA-Stack方案荣获了2017可信云大会“年度技术创新奖”,受到了业界的高度认可。
(赵锐演讲照片)
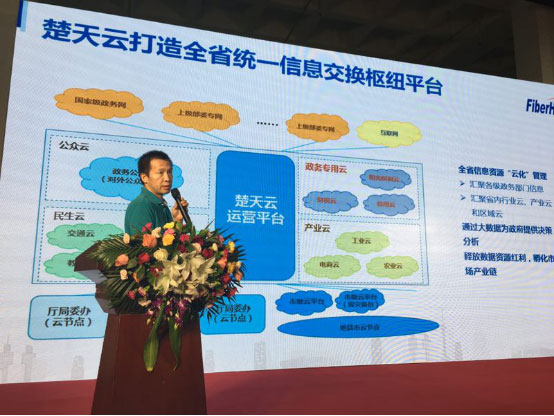
作为大型政务云的典型代表,烽火打造的楚天云是“智慧湖北”的龙头工程,是国内第一个贯通国家、省、市、县四级的数据交换及共享平台,也是国内第一个采用OpenStack开源架构为基础的省级政务云平台。目前,楚天云在现有基础设施及全省统一的政务网络体系基础之上,上联国家电子政务外网,横联104个厅局委办,下联17个地市州政务外网,打破部门壁垒、区域分割,变“信息孤岛”为“信息枢纽”,实现全省范围内的数据共享互通。
基于楚天云的战略地位及重要功能,如何保证楚天云业务连续运行就成为了最基础而又最重要的工作。在楚天云规划早期,烽火深入研究湖北省政府核心业务诉求,基于 FitCloud云网一体化解决方案提出了创新的建设思路。其中,烽火FitOS云操作系统是FitCloud的核心产品,该产品基于OpenStack组件进行深度优化及二次开发,在原生的基础上,增加虚拟机HA解决方案,通过采用分布式锁的防脑裂技术,在OpenStack外新增组件来实现主机和虚拟机故障场景下的虚拟机高可用。
在传统场景中,由故障检测不准确导致的主备虚机“脑裂”现象时常发生,在双机热备高可用(HA)系统中,当联系两个节点的“心跳线”断开时, 节点上的HA软件像“裂脑人”一样,本能地争抢“共享资源”、争起“应用服务”,就会导致共享资源被瓜分、两边“服务”都起不来,或者两边“服务”都起来了,但同时读写“共享存储”,最终导致数据损坏;另外,以往依赖IPMI来监测主机下电,当状态Off时,通过疏散虚拟机的接口(底层调用的Rebuild接口)来进行虚拟机HA重建,但无法解决主机掉电的场景,导致的数据面、业务面中断也无法解决。
为了在楚天云运行中避免出现传统故障场景,烽火FitOS虚拟机高可用解决方案中的防 “脑裂”方案基于分布式文件系统提供存储资源,底层使用SanLock锁提供防脑裂保护,保证磁盘同时只能有一处写入;此外,上层基于自研HA-Stack+Consul提供基于管理、存储、业务网络多平面探测,支持HA策略矩阵配置,基于QGA提供虚拟机内部异常检测(蓝屏、死机、业务网络中断等),同时超半数主机故障后,服务自动停止,防止故障扩散,当所有主机恢复后,服务将自动恢复。
目前,烽火云计算在政务、交通、教育、医疗等重点行业持续发力,并将基于用户场景提高云计算产品及解决方案中的智能化要素,帮助用户完成智能化的IT建设及业务运营,使得烽火成为具有持续创新性及竞争力的智慧城市建设领导者。
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2017
08/22
14:08
分享
点赞

机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
