
普元“自服务大数据资产管理”方案亮相第五届核电行业峰会
ZD至顶网CIO与应用频道 04月18日 北京消息:2017年4月14日,国内领先的基础软件开发平台与解决方案提供商普元信息,受邀出席于上海隆重举行的第五届中国核电信息技术高峰论坛。在此次以“聚焦核电信息化顶层设计,以两化融合促核电企业安全”为主题的行业权威峰会上,普元公司电力事业部副总经理王程志发表题为《“自服务大数据资产管理中心”支撑智慧核电建设--是智慧核电大数据分析应用的前提准备》的演讲。
演讲中,王程志结合普元在中核运行、中广核、国家电网、新奥能源等众多电力能源企业的大数据平台建设实施经验,分享普元助推智慧核电大数据分析应用有效实现“管的标准、用的便捷”的解决方案,以及普元如何帮助核电企业建设支撑智慧核电的可控的大数据创新应用。
智慧核电建设大势所趋,普元对大数据的管、用痛点剖析获众多专家认同
众所周知,2017年,国家能源局、国家发改委将国家能源应用技术研究及示范项目“智慧核电运营系统研究及示范项目”建设内容纳入了《能源技术创新 “十三五”规划》,我国智慧核电建设加快了建设步调。智慧核电建设作为“国家政策指导”和“行业发展战略”的共同要求,是核电产业传统运作模式拥抱大数据时代的大势所趋。
在拥有超过十年的电力、石油、燃气等能源行业平台产品与解决方案规划与设计经验的王程志看来,智慧核电建设与运营的关键支撑之一就是大数据的分析应用。他在演讲中指出,随着普元实践项目对大数据分析应用的深入,发现核电大数据在“管”和“用”方面存在诸多问题与挑战,比如数据资产目录的自助化管理、数据自助查询分析、数据的运营管理监控等等。
王程志通过分析强调,对于包括设计、建造、运营全过程多维度的核电数据管不“准”和用不“畅”成为制约智慧核电大数据分析应用的瓶颈,并最终导致业务技术之间的严重壁垒,数据应用不畅。这些痛点的强调,获得了很多与会专家的认同。
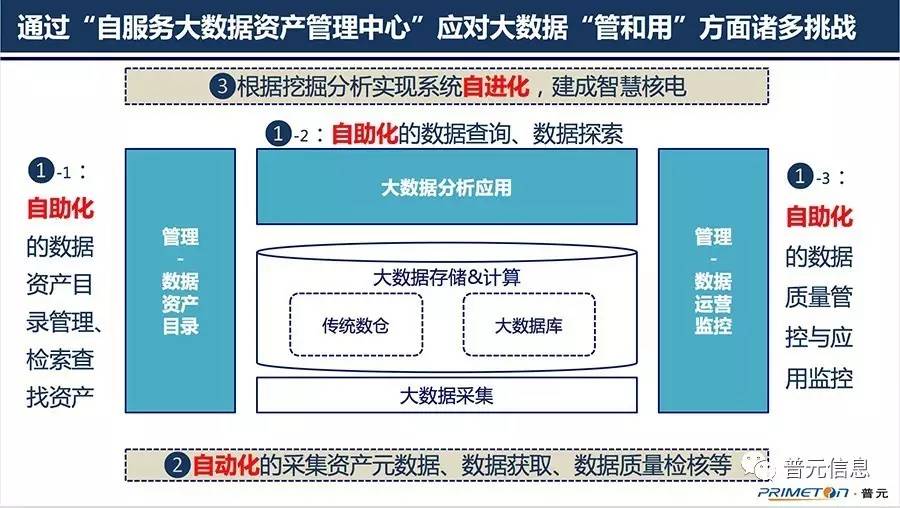
普元“自服务大数据资产管理中心”一站式解决方案支撑智慧核电建设
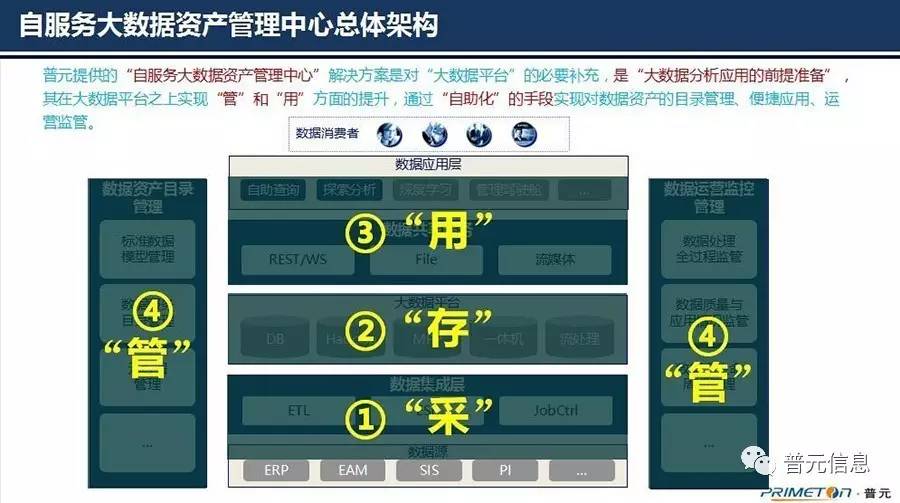
针对智慧核电大数据应用中的痛点问题,普元提出了“自服务大数据资产管理中心”一站式解决上述“管和用”方面诸多挑战,在大数据平台之上实现“管”和“用”方面的提升。
普元对“自服务大数据资产管理中心”从“自助化、自动化、自进化”三个方面进行解读。首先,“自助化”体现在自助化的数据资产目录管理、检索查找资产,自助化的数据查询分析、数据探索挖掘,自助化的数据质量管控与应用监控;其次,实现自助化的关键支撑之一是“自动化”的数据资产元数据采集、数据内容获取、数据质量检核等;最后,通过数据分析应用,实现系统自进化,建成智慧核电。
会上多位核电企业领导专家对普元“自服务大数据资产管理中心”表示了肯定,并积极与王程志交流。他们认为,普元提供的“自服务大数据资产管理中心”解决方案,在大数据平台之上实现了“管”和“用”方面的提升,为核电信息化标准化建设提供了有力支撑,通过“自助化”的手段实现了对数据资产的目录管理、便捷应用、运营监管。而全球最权威的 IT 咨询公司Gartner的数据也有力印证了普元解决方案的实践有效性。Gartner预测,到2019年,数据自服务的市场需求年复合增长率将达到16.6%。
在具体实践上,普元目前已帮助众多电力能源企业开展大数据平台建设,打造智慧能源企业,如国家电网、中广核、中核运行、国电集团、新奥能源等。
丰富的经验是优良的资质,
拥有“中核集团合格供应商证书”的普元,已有多款产品在核电这一国家战略行业进行供应服务。王程志还在本届核电信息技术高峰论坛上坦言,普元将进一步提升云数据平台、数字化企业云平台等智慧核电建设的关键支撑平台,用普元在国产信息化领域的多年实践积累助力智慧核电建设的进一步发展。
好文章,需要你的鼓励


研究人员利用300万天Apple Watch数据训练疾病检测AI
研究人员基于Meta前首席AI科学家Yann LeCun提出的联合嵌入预测架构,开发了名为JETS的自监督时间序列基础模型。该模型能够处理不规则的可穿戴设备数据,通过学习预测缺失数据的含义而非数据本身,成功检测多种疾病。在高血压检测中AUROC达86.8%,心房扑动检测达70.5%。研究显示即使只有15%的参与者有标注医疗记录,该模型仍能有效利用85%的未标注数据进行训练,为利用不完整健康数据提供了新思路。

西湖大学与清华大学联合发布TwinFlow:让AI图像生成秒变魔术,一步搞定原本需要100步的任务
西湖大学等机构联合发布TwinFlow技术,通过创新的"双轨道"设计实现AI图像生成的革命性突破。该技术让原本需要40-100步的图像生成过程缩短到仅需1步,速度提升100倍且质量几乎无损。TwinFlow采用自我对抗机制,无需额外辅助模型,成功应用于200亿参数超大模型,在GenEval等标准测试中表现卓越,为实时AI图像生成应用开辟了广阔前景。

CoreWeave CEO 为 AI 循环交易辩护称其为“协作共赢“
AI云基础设施提供商Coreweave今年经历了起伏。3月份IPO未达预期,10月收购Core Scientific计划因股东反对而搁浅。CEO Michael Intrator为公司表现辩护,称正在创建云计算新商业模式。面对股价波动和高负债质疑,他表示这是颠覆性创新的必然过程。公司从加密货币挖矿转型为AI基础设施提供商,与微软、OpenAI等巨头合作。对于AI行业循环投资批评,Intrator认为这是应对供需剧变的合作方式。

当AI学会分辨真假照片:中山大学团队让图像生成器彻底告别“塑料感“
中山大学等机构联合开发的RealGen框架成功解决了AI生成图像的"塑料感"问题。该技术通过"探测器奖励"机制,让AI在躲避图像检测器识别的过程中学会制作更逼真照片。实验显示,RealGen在逼真度评测中大幅领先现有模型,在与真实照片对比中胜率接近50%,为AI图像生成技术带来重要突破。
2017
04/18
10:08
分享
点赞

智算前沿 焕芯未来—MINISFORUM 与 AMD 联合举办AI 双旗舰产品体验会
锐龙9高端游戏本突破百万销量 京东“超级供应链”成AMD 增长强引擎
西门子发布数据中心解决方案5.0,创新型直流配电产品首次亮相中国市场
研究人员利用300万天Apple Watch数据训练疾病检测AI
CoreWeave CEO 为 AI 循环交易辩护称其为"协作共赢"
IT领导者不可忽视的生成式AI价值实现五大趋势
AI安全监管亟待加强,头部科技公司评分不及格
TPU挑战GPU霸主地位,谷歌专用芯片崛起
2026年AI预测:自动化发展与工作未来的十大趋势
亚马逊计划2030年前在印度投资350亿美元聚焦AI与物流
Adobe将Photoshop、Acrobat和Adobe Express集成至ChatGPT
Google DeepMind与Apptronik展示家用人形机器人执行真实世界任务
