
云数据恢复:文档是成功的关键
创建云上的数据恢复计划,很重要的一点是持续跟踪基础架构,DR需求和可能的故障转移持续时间。
公有云给IT部门提供了绝佳的机会来实现业务的持续性/灾难恢复计划,而无需花费巨资构建独享的数据中心。有了云数据恢复系统之后,云就可以用作基本数据的存储库或者甚至当主要系统出问题时运行应用之处。
当构建DR计划时,第一步是查看用来交付IT服务的应用,并且决定灾难发生时需要保护什么。这意味着创建需要运行的应用和服务的清单。很多企业已经转向虚拟化作为其核心服务器的部署模型;但是,仍然需要考虑物理服务器。完善的云数据恢复计划应该包括如下:
用来交付基础架构的物理和虚拟服务器。这些包括活动目录(AD)服务器,DNS/DNCP服务器和应用。
- 用来交付应用的物理服务器。为什么还在物理服务器上交付服务,这需要有好一点的理由;这可能包括扩展和性能要求,或者使用自定义硬件和操作系统。但是,云恢复服务可能能够帮助虚拟化其中一些组件。
- 用来交付应用的虚拟服务器。可能有几十台或者上百台虚拟机用来实现应用。每台都需要确认和记录、查看存储、内存和虚拟处理器需求。
最好提前确定基础架构服务器,因为当灾难发生时这些系统需要第一时间恢复服务。可以预配置在云上运行的AD、DNS和DNCP服务,并且和它们的内部实例同步,让DR流程更加容易,也能够更快实现。
要想让云上的DR能够成功工作,理解网络配置至关重要。这意味着需要花时间理解网络层的应用之间的相互依赖关系,包括安全和防火墙配置。云数据恢复相关的问题有:
- 是否有应用或者服务器互相之间有延迟依赖?
- 是否有East-West防火墙规则来管理站内流量?
- 面向客户的应用的外部带宽需求是什么?
确定云数据恢复需求
假定在灾难事件发生时,每个应用都需要立即恢复,这并不太实际。相反,应该基于一系列条件来区分应用的优先级,来决定需要多快,以及哪些同步系统和数据需要恢复运营。在决定恢复应用的服务等级时,可以使用一些标准来进行度量:
- 恢复时间目标。它衡量在应序备份并且运行之前可以容忍多长的下线时间;通常以分钟或者小时计量。比如,零RTO表示完全不能容忍掉线,而一小时的RTO意味着应用必须在DR发生的一小时内完成恢复。
- 恢复点目标。它衡量一旦应用再次运行时可以容忍丢失多少数据。零RPO意味着所有数据都必须恢复到灾难发生点,而24小时的RTO意味着恢复后数据或系统可以过时24小时。
- 服务级别目标。SLO衡量整体应用的恢复情况。比如,协议可能是在四小时内恢复90%的应用。越严格的SLO要求越多的基础架构支撑并且可能需要越多的人力才能达到,因此留有一定的灵活度有助于管理DR的费用。
- SLO 允许区分数据和应用的优先级。比如,一个在线信用卡处理系统要求零RPO和非常低的RTO。期望这样的系统永远也不会丢失信息是合理的。另一种极端情 况是,负责报告的应用可能能够容忍24到48小时的数据过期时间,因为其数据是从其他应用里抽取出来的。其他系统大多数处在这两种极端情况之间。
建立正确的云数据恢复需求包括和应用程序的业务所有者沟通,因为他们了解其应用的重要程度。从经验上看,业务所有者会认为其所有应用都很重要——直到他们了解恢复所需的费用为止。因此可以告诉他们不同方案的费用评估。
服务级别的最后一点是:一些严格的需求,比如零PRO,基于云的DR是无法达成的,因为本地和云位置之间会有延时。需要将这些应用排除在基于云的DR之外,并且提供更多定制的DR产品。
DR服务会运行多久?
最后需要讨论的是,服务会在公有云上运行多久。做这样的决策依赖于发生的事件类型。并非所有灾难都会导致所有在线功能的崩溃。还会存在一些边缘事件类型,比如:
- 服务器丢失。要么是物理服务器,要么是虚拟服务器主机。虚拟服务器的丢失可能很严重,但也可能不严重,应用程序需要转而运行在DR模式。
- 多系统丢失。比如,如果共享存储阵列出问题的话,可能会失去多个应用。
- 数据中心丢失。在最坏的情况下,整个数据中心都丢失了,或者访问不了。所有服务都需要运行在DR模式下。
有时候,服务需要移动几个小时或者几天。当整个站点都丢失时,需求可能是运行DR服务几周或者几个月,直到重建了之前的设备。云恢复服务会为所使用的活动服务计费,因此在选择DR服务时这是很重要的考核点。
好文章,需要你的鼓励

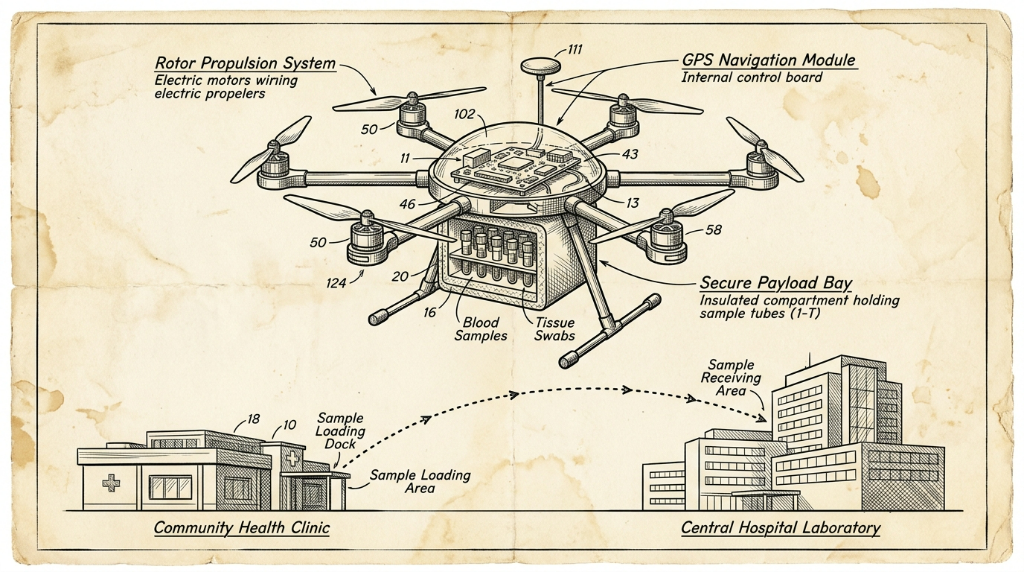
英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。
2016
05/26
10:08
分享
点赞

WAIC2026 现场直击:开普勒顶流人气王,麒麟系列火爆出圈
面壁智能将密度定律带入具身智能
龙磁科技拟投3.58亿元扩建越南永磁铁氧体基地
首创一层Scale-up网络256卡全互联,摩尔线程MTT C256超节点为万卡及十万卡级集群夯实底座
从高血压诊疗入手,北京安贞医院让医疗大模型走出聊天框
西门子肖松:以场景为牵引,推动工业AI从单点实效迈向生产力跃迁
打造Token极致性价比 新华三震撼亮相2026世界人工智能大会
机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
