
腾讯混元图像2.0模型正式发布
AI图像生成进入“毫秒级”时代。
5月16日,腾讯发布最新混元图像2.0模型(Hunyuan Image2.0),基于模型架构创新,在行业内率先实现实时生图,在画面质感超写实的基础上,带来全新的AI生图交互体验。模型于即日起在腾讯混元官方网站上线,并对外开放注册体验。

相比前代模型,腾讯混元图像2.0模型参数量提升了一个数量级,得益于超高压缩倍率的图像编解码器以及全新扩散架构,其生图速度显著快于行业领先模型,在同类商业产品每张图推理速度需要5到10秒的情况下,腾讯混元可实现毫秒级响应,支持用户可以一边打字或者一边说话一边出图,改变了传统“抽卡—等待—抽卡”的方式,带来交互体验革新。
除了速度快以外,腾讯混元图像2.0模型图像生成质量提升明显,通过强化学习等算法以及引入大量人类美学知识对齐,生成的图像可有效避免AIGC图像中的"AI味“ ,真实感强、细节丰富、可用性高。
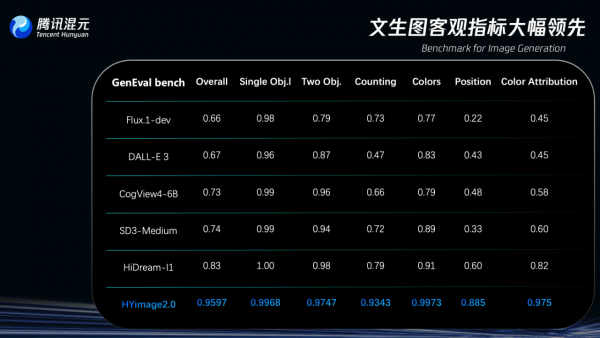
在图像生成领域专门测试模型复杂文本指令理解与生成能力的评估基准
GenEval(Geneval Bench)上,腾讯混元图像2.0模型准确率超过95%,远超其他同类模型。
在腾讯混元的发布直播中,官方演示了多个不同风格的图片生成效果,除了速度快以外,生成的图片在人物特写、动物特写、复古摄影等领域都有很不错的表现,体现出电影级别质感画面水准。

人像摄影风格

复古摄影

动漫风格

真实人物风格
腾讯混元图像2.0模型还发布了实时绘画板功能,基于模型的实时生图能力,用户在绘制线稿或调整参数时,预览区同步生成上色效果,突破了传统“绘制-等待-修改”的线性流程,可助力专业设计师的创作。
实时绘画板支持多图融合,用户上传多图后,可将多个草图叠加至同一画布自由创作,经过AI 自动协调透视与光影,按照提示词内容生成融合图像,进一步丰富了AI生图的交互体验。
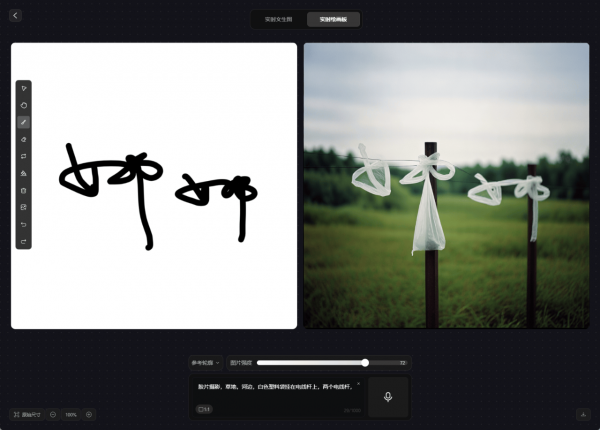
图源自创作者一只小娜娜
发布会上,腾讯混元也剧透了即将发布的原生多模态图像生成大模型,新模型在多轮图像生成、实时交互体验等方面有突出表现。
腾讯混元在图像、视频等模态上持续投入,于2014年率先推出并开源了业内首个中文原生的DiT架构文生图开源模型以及参数量达130亿的腾讯混元视频生成大模型。混元图像生成2.0 模型的发布,是腾讯混元在多模态领域的又一里程碑事件。
来源:至顶网CIO与CTO频道
好文章,需要你的鼓励



Queen‘s大学重磅研究:程序员的角色即将彻底改变,从码农到智能体指挥官
Queen's大学研究团队提出结构化智能体软件工程框架SASE,重新定义人机协作模式。该框架将程序员角色从代码编写者转变为AI团队指挥者,建立双向咨询机制和标准化文档系统,解决AI编程中的质量控制难题,为软件工程向智能化协作时代转型提供系统性解决方案。

苹果发布 iOS 26.0.1 系统更新,修复多项关键问题
苹果在iOS 26公开发布两周后推出首个修复更新iOS 26.0.1,建议所有用户安装。由于重大版本发布通常伴随漏洞,许多用户此前选择安装iOS 18.7。尽管iOS 26经过数月测试,但更大用户基数能发现更多问题。新版本与iPhone 17等新机型同期发布,测试范围此前受限。预计苹果将继续发布后续修复版本。

医疗AI的“显微镜革命“:西北工业大学团队发布首个超声影像专用智能助手EchoVLM
西北工业大学与中山大学合作开发了首个超声专用AI视觉语言模型EchoVLM,通过收集15家医院20万病例和147万超声图像,采用专家混合架构,实现了比通用AI模型准确率提升10分以上的突破。该系统能自动生成超声报告、进行诊断分析和回答专业问题,为医生提供智能辅助,推动医疗AI向专业化发展。
2025
05/16
14:02
分享
点赞

业界首款符合AEC-Q200标准额定电压高达1,000 VDC高压保险丝
数据中心的智算挑战,英特尔要如何应对?
下一代智能工厂怎么建?开放自动化给出“解题思路”
跟随西门子,在工博会感受沉浸式的工业AI体验
苹果发布 iOS 26.0.1 系统更新,修复多项关键问题
OpenAI将发布类似TikTok的社交应用,搭配Sora 2视频模型
微软推出Office智能体模式让用户"氛围办公"
AI助手现在能帮你创建高质量Word文档和Excel表格
高通新一代骁龙平台将推动智能体AI时代到来
SAPx阿里云,开启一条通往中国市场与全球化发展的全新路径
微软推出"氛围工作"模式,为Office套件加入AI智能体
OpenAI推出智能购物系统挑战谷歌亚马逊
