
Jetson Nano 2GB 系列(26):“Hello AI World”物件检测的模型训练
与前面“图像分类的模型训练”几乎完全一致的步骤,本文要带着大家来建立自己专属的物件检测模型,这是实用性较高的部分,因为物件检测的应用比较接地气,能轻易地与生活周遭的场景相结合,所以以“物件检测的模型训练”作为 “Hello AI World” 系列文章的结尾,是非常有意义的事情。
任何应用的模型训练,都必须从“数据集的收集与整理”开始。前面“图像分类模型训练”里使用的是 KITTI 数据集格式,至于物件检测所使用的数据集,就比图像分类要复杂很多,虽然“图像”本身可以是一样的,但是在每张图形上都必须更进一步地将所需要检测的物件“标注(annotate)”出来,目前已经有非常多的“图像标注工具”可以使用。
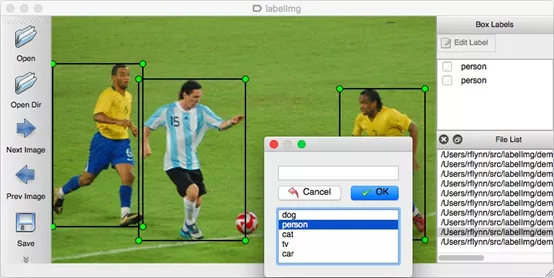
下图就是使用 labelimg 这个开源工具对图像进行标注的任务,将每个标注的图框给与指定的单一分类,每张图形都可能有多个分类与多个物件,标框的原则也会影响将来的推理结果,如果标框过程比较粗糙(边界界定不清楚),后面得到的结果也会比较粗糙。
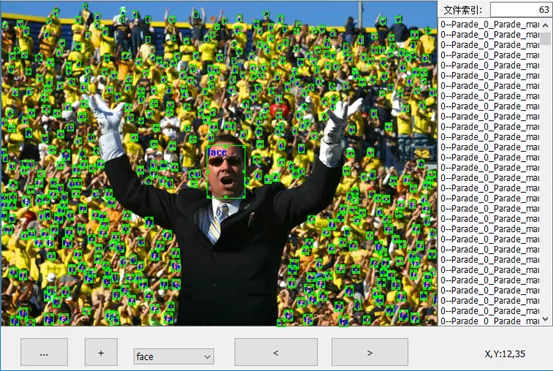
下面一张图是比较极端的,在一张图像中标注出上百个“face”类别的物件。
这个标注过程的工作量比简单的图像分类要高出许多倍,但是如果要做出属于自己的应用,这个过程必不可少。
由于各种数据集之间的结构并不一致,目前使用率较高的主要是 Pascal VOC、MS-COCO 与 Google OpenImages 这几个数据集,在 Hello AI World 项目的物件检测模型训练工具里,内建支持 VOC 与 OpenImages 这两种格式,因此这里的实验也主要以这两种格式为主,如果您手边有其他格式的数据集,可以透过网上很多工具,或者上传到 http://roboflow.com 去进行格式转换。
项目虽然提供 camera-capture 这个“现场抓图”的工具(如下图),但只能接受摄像头这个输入源,缺乏对单张图像进行标注功能,因此只能作为教学用途或者数据集补充功能,并不适合做批量的图像标注任务。

一开始实验之前,请先执行以下三个步骤:

接下来分别以 VOC 格式与 OpenImages 格式的数据集做范例,分别进行整个模型训练的过程,这两种类型的执行差异,只有第一步的“数据集准备”有所不同,后面的“模型训练”、“转成ONNX格式”与“推理识别”等部分的步骤是完全一样的。
Step 1:准备与整理数据集
进到工作目录之后,下面已经预先开好 data 与 models 两个子目录,后面的实验会将数据部分放在 data 目录下的对应项目中,训练的模型会放到 models 下的对应项目中。
- VOC数据集格式
由于这种格式算得上是物件检测数据集的鼻祖,并且格式相对简单,因此通用性较高,绝大部分数据集格式都能透过转换工具,转成 VOC 格式。为了比较贴近实际生活的体验,这里使用一个我们建立的“口罩识别”数据集:

按照 VOC 数据结构,必须具备以下元素:

1) Annotations目录:存放全部的标注文件(*.xml)
2)ImageSets/Main:下面主要是 2 个.txt文件
- test.txt:存放“测试”用的文件名(不用附加档名),数量自定,通常建议是整个数据集的20%左右比例,各种类别都需要涵盖。
- trainval.txt:存放“训练&校验”用的文件名列表,约占整个数据集的80%。
3) JPEGImages目录:存放全部图片数据(*.jpg、*.jpeg、*.gif等)
4)labels.txt:数据集的类别,本范例中只有“Mask”与“No_Mask”两个。
如果有自己建立的其他数据集,例如从其他数据集截取,或者 camera-capture 工具直接获得的,只要整理成上述的 VOC 结构,就能被本项目 train_ssd.py 代码所使用。
- OpenImages数据集格式
这个数据集的标注文件内容可能是目前最复杂的,不过数据内容丰富,能有效利用起来是非常好的。这个项目的作者为 OpenImages 数据集的部分数据抽取用途,提供一只专门的 open_images_downloader.py代码,去下载特定类别的数据集与标注文件。
例如,我们想收集“水果(fruit)”数据并进行训练,这些水果包括“苹果(apple),橘子(orange),香蕉(banana),草莓(Strawberry),葡萄(Grape),梨(Pear),菠萝(Pineapple),西瓜(Watermelon)”这八种,

--data:数据存放的地方
--class-names:要下载的类别,这里比较麻烦的是,OpenImages总共有600个类别,可以到https://github.com/dusty-nv/pytorch-ssd/blob/master/open_images_classes.txt 先查清楚想要下载哪些类别
其余比较重要的参数:
--stats-only:加上这个参数,可以“预览”每个类别的图像数量,但还不执行下载。下图显示在train/validation/test三类的图像数量与标注(boxes)数量的统计表。
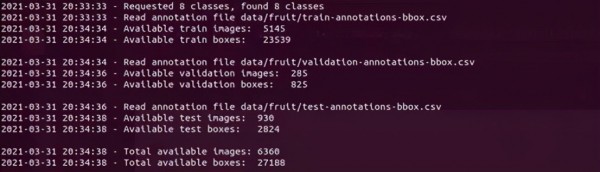
--max-images:避免太多的数据集下载,可用这个参数限制数量,如果本次下载数据集不做数量限制的话,总共会下载6360张图片与27188个标注信息。
下面列出下载完的数据结构(如下图),里面有 test/train/validation 三个子目录,将下载的图像分配到这三个目录里面,其中 train 占 80%、test 占 15%、validation 占 5% ,大约是这样的比例分配。
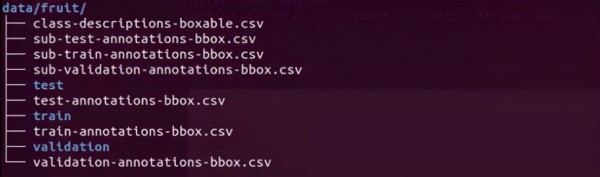
至于另外 7 个.csv文件中,class-descriptions-boxable.csv 存放 OpenImages 的 600 种类别,其他 6 个则包含对应于 train/test/validation 三种用途的标注数据,内容相当艰涩复杂,这里就不做探索。
Step 2:搭配学习功能训练模型
数据集的准备与整理,是整个模型训练中最耗费人力的部分,虽然接下去的部分执行步骤相当简单,不过却是最耗费计算资源的阶段,还好本项目支持 Pytorch 的迁移学习功能,这为我们节省非常多的计算时间。
train_ssd.py 训练代码中已设定好以 SSD 这个网络模型为基础,提供一个以 80 类 COCO 数据集预训练好的
mobilenet-v1-ssd-mp-0_675.pth 为基础,去训练您的模型,这个模型在一开始的时候已经下载到对应的位置。
接下去我们只要根据“数据集格式”去选择参数,执行训练指令就可以:

简单说明一下 train_ssd.py 的重要参数:
--data:数据集存放的地方(输入)
--model-dir:存放生成模型的地方(输出)
--database-type:数据集种类,支持VOC与OpenImages(预设值)
--epoch:训练的次数,预设值为30
--batch-size:预设为4,在Nano(含2GB)上可改成2
每个 epoch 训练完,都会生成一个对应的 xxx-Epoch-n-xxxx.pth 文件。这个过程不仅消耗计算资源,而且对内存需求量很大,执行过程如果遇到中途中断,或者 “LOSS” 出现 “nan” 时,可能是内存不足所导致,这时候就需要增加 SWAP 空间,并且关闭图像桌面,将资源留给模型训练。
Step 3:将模型文件转换成.onnx格式
这个步骤虽然十分简单,但很重要,因为这是将我们自己训练的模型,能调用 TensorRT 加速引擎的最便利方法。使用的指令如下,下面以口罩识别项目为例:
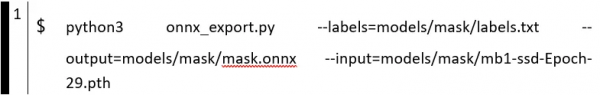
这里选择的 --input 通常以训练中 Loss 数字最小的那个模型文件,将他转换成指定路径的 .onnx 即可。
Step 4:推理识别
这部分使用大家都应该已经很熟悉的 detectnet 指令,前面应使用内建的网络模型,因此只要指定 --network 就能得到配套的参数。但是现在不一样的是,要是用我们自己建立的模型文件,因此很多参数都得自己设定,其实也不是太复杂,参考以下的指令:

指令中的 --input-blod、--output-cvg、--output-bbox 这三个参数,依照本范例的值去给定就可以。其他 --model、--labels 根据实际状况进行调整,最后的 /dev/video0 也根据实际数据源进行改变。
来源:至顶网CIO与CTO频道
好文章,需要你的鼓励


LibreOffice 25.8发布:性能提升并支持PDF 2.0
LibreOffice 25.8版本以"更智能、更快速、更可靠"为特色正式发布。新版本在多个方面实现性能优化,包括启动速度、文档滚动和文件打开速度的显著提升。该版本增强了对微软Office文档格式的兼容性,改进了连字符处理和字体兼容性,Calc表格组件新增十多个函数以更好支持Excel文件导入。值得注意的是,LibreOffice 25.8首次支持PDF 2.0格式导出,并具备PDF数字加密和签名功能。新版本提高了系统要求,不再支持Windows 7/8系列和32位系统。

谷歌AI团队揭秘:机器人如何用ChatGPT般的“大脑“学会在真实世界中导航
谷歌DeepMind团队开发出ViNT视觉导航系统,让机器人像人类一样仅通过"看"就能在陌生环境中导航。该系统模仿ChatGPT的学习方式,通过分析600万个导航轨迹掌握通用导航能力,在未知环境中的成功率达87%。这一突破将推动物流配送、家庭服务、搜救等领域的机器人应用发展。

微软AI高管称研究AI意识问题是“危险的“
微软AI首席执行官苏莱曼发文称,研究AI福利和意识"既不成熟又危险",认为这会加剧人类对AI的不健康依赖。而Anthropic、OpenAI等公司正积极研究AI意识问题,招聘相关研究人员。业界对AI是否会产生主观体验及其权利问题分歧严重。前OpenAI员工认为可以同时关注多个问题,善待AI模型成本低且有益。随着AI系统改进,关于AI权利和意识的辩论预计将升温。

谷歌DeepMind的AlphaFold3重大突破:让原本需要数年研究的生物分子结构预测变得像查字典一样简单
谷歌DeepMind推出AlphaFold3,革命性提升分子结构预测能力。该AI模型采用创新扩散网络架构,能够精确预测蛋白质与DNA、RNA、药物等分子的相互作用,准确率比传统方法提高50%以上。这一突破将显著加速新药开发,推动基础科学研究,并通过免费开放服务促进全球科研合作,标志着生命科学研究进入AI驱动的新时代。
2021
09/14
17:30
分享
点赞

Hot Chips|NVIDIA的下一块“未来版图” Spectrum-XGS 定义“行星级”AI超级工厂
英特尔携手亚马逊云科技,以至强6处理器驱动云服务创新
LibreOffice 25.8发布:性能提升并支持PDF 2.0
微软AI高管称研究AI意识问题是"危险的"
谷歌AI搜索模式全球扩展推出智能体预订功能
PCIe 7.0和8.0标准即将到来,超高速连接2028年实现
基于事件驱动的智能体AI重塑企业资源规划系统
微软研究院推出革命性提示词语言POML:普通开发者也能轻松驾驭大模型
从AI崛起到智算中心腾飞,电力保障如何重新定义未来
机器人软件创企FieldAI获4.05亿美元融资
Epic发布医疗智能体系统重新定义健康产业生态
量子即服务(QaaS)正在改变企业获取量子计算能力的方式
