
腾讯混元图像2.0模型正式发布
AI图像生成进入“毫秒级”时代。
5月16日,腾讯发布最新混元图像2.0模型(Hunyuan Image2.0),基于模型架构创新,在行业内率先实现实时生图,在画面质感超写实的基础上,带来全新的AI生图交互体验。模型于即日起在腾讯混元官方网站上线,并对外开放注册体验。

相比前代模型,腾讯混元图像2.0模型参数量提升了一个数量级,得益于超高压缩倍率的图像编解码器以及全新扩散架构,其生图速度显著快于行业领先模型,在同类商业产品每张图推理速度需要5到10秒的情况下,腾讯混元可实现毫秒级响应,支持用户可以一边打字或者一边说话一边出图,改变了传统“抽卡—等待—抽卡”的方式,带来交互体验革新。
除了速度快以外,腾讯混元图像2.0模型图像生成质量提升明显,通过强化学习等算法以及引入大量人类美学知识对齐,生成的图像可有效避免AIGC图像中的"AI味“ ,真实感强、细节丰富、可用性高。
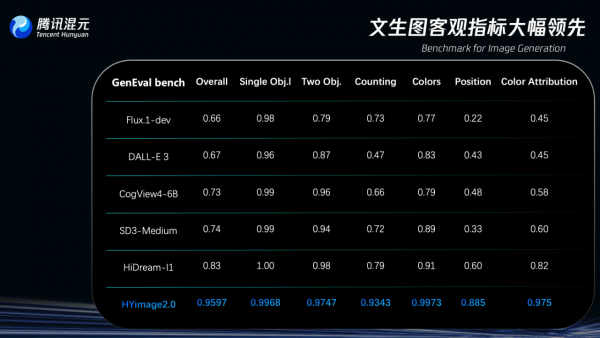
在图像生成领域专门测试模型复杂文本指令理解与生成能力的评估基准
GenEval(Geneval Bench)上,腾讯混元图像2.0模型准确率超过95%,远超其他同类模型。
在腾讯混元的发布直播中,官方演示了多个不同风格的图片生成效果,除了速度快以外,生成的图片在人物特写、动物特写、复古摄影等领域都有很不错的表现,体现出电影级别质感画面水准。

人像摄影风格

复古摄影

动漫风格

真实人物风格
腾讯混元图像2.0模型还发布了实时绘画板功能,基于模型的实时生图能力,用户在绘制线稿或调整参数时,预览区同步生成上色效果,突破了传统“绘制-等待-修改”的线性流程,可助力专业设计师的创作。
实时绘画板支持多图融合,用户上传多图后,可将多个草图叠加至同一画布自由创作,经过AI 自动协调透视与光影,按照提示词内容生成融合图像,进一步丰富了AI生图的交互体验。
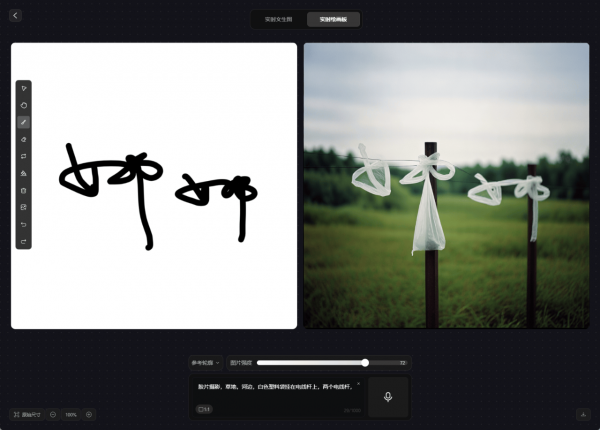
图源自创作者一只小娜娜
发布会上,腾讯混元也剧透了即将发布的原生多模态图像生成大模型,新模型在多轮图像生成、实时交互体验等方面有突出表现。
腾讯混元在图像、视频等模态上持续投入,于2014年率先推出并开源了业内首个中文原生的DiT架构文生图开源模型以及参数量达130亿的腾讯混元视频生成大模型。混元图像生成2.0 模型的发布,是腾讯混元在多模态领域的又一里程碑事件。
来源:至顶网CIO与CTO频道
好文章,需要你的鼓励


研究人员利用300万天Apple Watch数据训练疾病检测AI
研究人员基于Meta前首席AI科学家Yann LeCun提出的联合嵌入预测架构,开发了名为JETS的自监督时间序列基础模型。该模型能够处理不规则的可穿戴设备数据,通过学习预测缺失数据的含义而非数据本身,成功检测多种疾病。在高血压检测中AUROC达86.8%,心房扑动检测达70.5%。研究显示即使只有15%的参与者有标注医疗记录,该模型仍能有效利用85%的未标注数据进行训练,为利用不完整健康数据提供了新思路。

西湖大学与清华大学联合发布TwinFlow:让AI图像生成秒变魔术,一步搞定原本需要100步的任务
西湖大学等机构联合发布TwinFlow技术,通过创新的"双轨道"设计实现AI图像生成的革命性突破。该技术让原本需要40-100步的图像生成过程缩短到仅需1步,速度提升100倍且质量几乎无损。TwinFlow采用自我对抗机制,无需额外辅助模型,成功应用于200亿参数超大模型,在GenEval等标准测试中表现卓越,为实时AI图像生成应用开辟了广阔前景。

CoreWeave CEO 为 AI 循环交易辩护称其为“协作共赢“
AI云基础设施提供商Coreweave今年经历了起伏。3月份IPO未达预期,10月收购Core Scientific计划因股东反对而搁浅。CEO Michael Intrator为公司表现辩护,称正在创建云计算新商业模式。面对股价波动和高负债质疑,他表示这是颠覆性创新的必然过程。公司从加密货币挖矿转型为AI基础设施提供商,与微软、OpenAI等巨头合作。对于AI行业循环投资批评,Intrator认为这是应对供需剧变的合作方式。

当AI学会分辨真假照片:中山大学团队让图像生成器彻底告别“塑料感“
中山大学等机构联合开发的RealGen框架成功解决了AI生成图像的"塑料感"问题。该技术通过"探测器奖励"机制,让AI在躲避图像检测器识别的过程中学会制作更逼真照片。实验显示,RealGen在逼真度评测中大幅领先现有模型,在与真实照片对比中胜率接近50%,为AI图像生成技术带来重要突破。
2025
05/16
14:02
分享
点赞

智算前沿 焕芯未来—MINISFORUM 与 AMD 联合举办AI 双旗舰产品体验会
锐龙9高端游戏本突破百万销量 京东“超级供应链”成AMD 增长强引擎
西门子发布数据中心解决方案5.0,创新型直流配电产品首次亮相中国市场
研究人员利用300万天Apple Watch数据训练疾病检测AI
CoreWeave CEO 为 AI 循环交易辩护称其为"协作共赢"
IT领导者不可忽视的生成式AI价值实现五大趋势
AI安全监管亟待加强,头部科技公司评分不及格
TPU挑战GPU霸主地位,谷歌专用芯片崛起
2026年AI预测:自动化发展与工作未来的十大趋势
亚马逊计划2030年前在印度投资350亿美元聚焦AI与物流
Adobe将Photoshop、Acrobat和Adobe Express集成至ChatGPT
Google DeepMind与Apptronik展示家用人形机器人执行真实世界任务
