
做好数据安全治理,保护企业数据资产!
数字化时代,数据已经成为企业和个人最重要的资产之一。
2023年12月15日,国家数据局发布了《“数据要素×”三年行动计划(2024—2026年)(征求意见稿)》,明确指出要充分发挥数据要素的放大、叠加、倍增作用,构建以数据为关键要素的数字经济,推动企业高质量发展。
数据给社会带来了前所未有的发展机遇,也带了前所未有的数据安全挑战。如2018年Facebook被曝光将数百万用户的个人信息泄露给了第三方,引发了全球范围内的隐私和数据保护问题,类似的数据安全事件日益增多。因此,如何保护数据安全成为了一个亟待解决的问题。
首先,我们需要明确什么是数据安全。数据安全是数据的质量属性,其目标是保障数据资产的保密性、完整性和可用性。如下图所示:
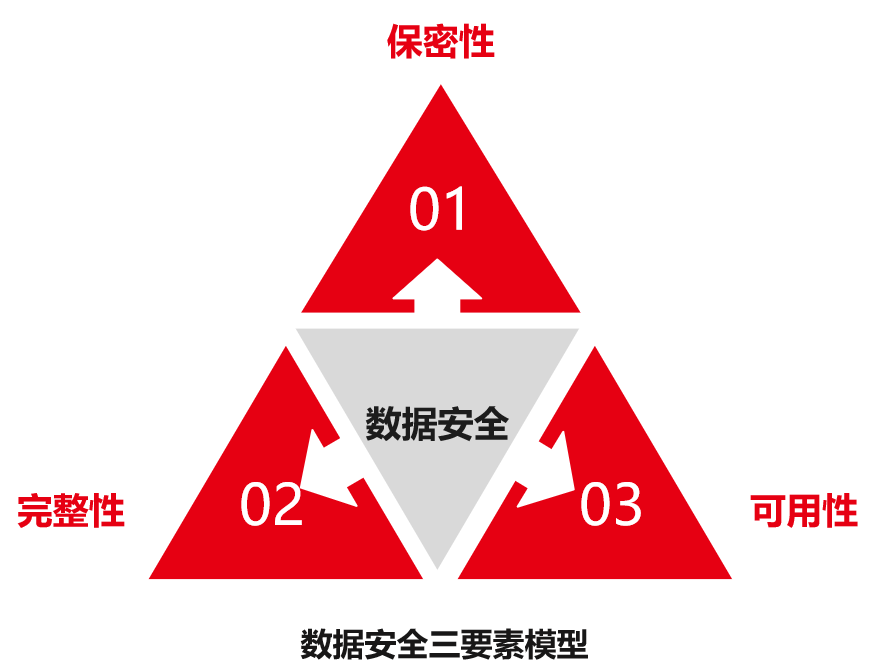
保密性:数据保密性又称数据机密性,是指个人或组织的信息不为未授权者获得,确保只有授权人员才能合法访问数据。
完整性:数据完整性是指在传输、存储或使用数据的过程中,保障数据不被篡改或被篡改后能够迅速被发现,从而确保信息可靠且准确。
可用性:数据可用性是一种以用户为中心的概念,确保数据既可用又可以访问满足业务需求。
数据安全治理是在数据安全标准与策略的指导下,通过对数据访问的授权、分类分级的控制,监控数据的访问等进行数据安全的治理工作,确保数据的可用性、完整性和保密性,满足数据安全的业务需要和监管需求,实现组织内部对数据生命周期的数据安全管理。
用友是全球领先的企业数智化软件与服务提供商,具有丰富的数据治理经验,沉淀了一套涵盖数据全生命周期的数据安全治理体系,帮助企业高效构建数字防火墙,让数据安全治理从“无序”到“有序”,从“人治”到“法治”,有效保障企业数据资产。如下图所示:
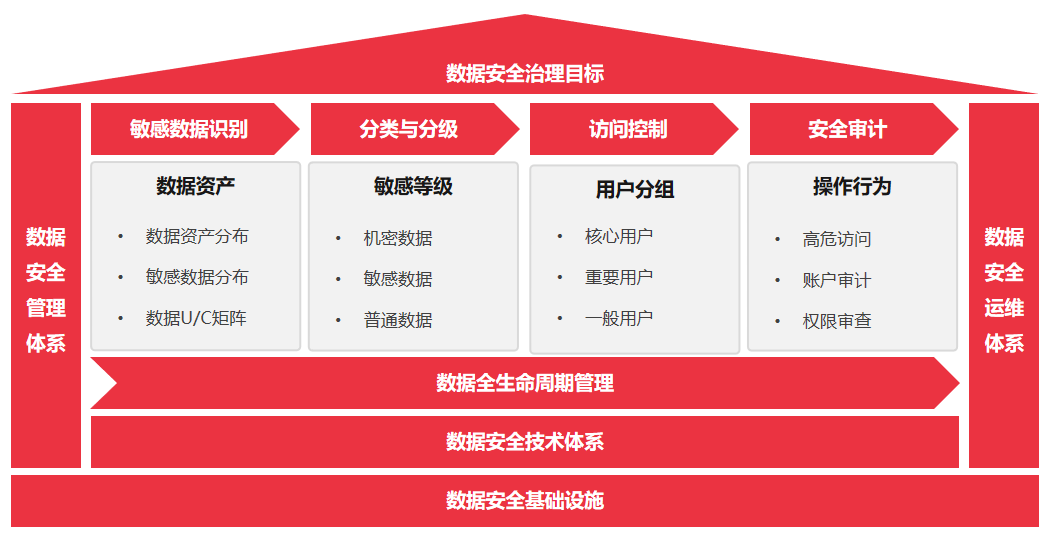
1、数据安全治理目标:数据安全治理的目标是保障数据可用性、完整性、保密性及合规使用,为业务目标的实现保驾护航。强调安全目标与业务目标的一致性。
2、数据安全管理体系:主要包括组织、人员、数据安全认责策略、数据安全管理流程制度等。
3、数据安全技术体系:主要包括数据全生命周期的敏感数据识别、数据分类与分级、数据访问控制、数据安全审计等。
4、数据安全运维体系:主要包括定期稽核策略、动态防护策略、数据备份策略、数据安全培训等。
5、数据安全基础设施:重点强调数据所在宿主机器的物理安全和网络安全。
在数据安全治理体系架构中,数据安全策略是核心,数据安全管理体系是基础,数据安全技术体系为支撑,数据安全运维体系是应用。数据安全策略通过管理体系制定、通过技术体系创建,通过安全运维体系执行。
传统的数据安全治理更多是防止数据丢失和访问审计等。在数字化时代,用友认为数据安全治理应该以数据为中心,建设“可见、可控、可管”的能力,让企业的数据资产看得见、控得住、管得好。

数据安全治理伴随数据采集、存储、加工、应用全过程。工欲善其事,必先利其器,企业要想数据安全治理常态化运行,需要一套自动化、便捷化的数据治理工具支撑,实现流程、业务和技术的有效融合,确保数据安全策略能刚性落地。
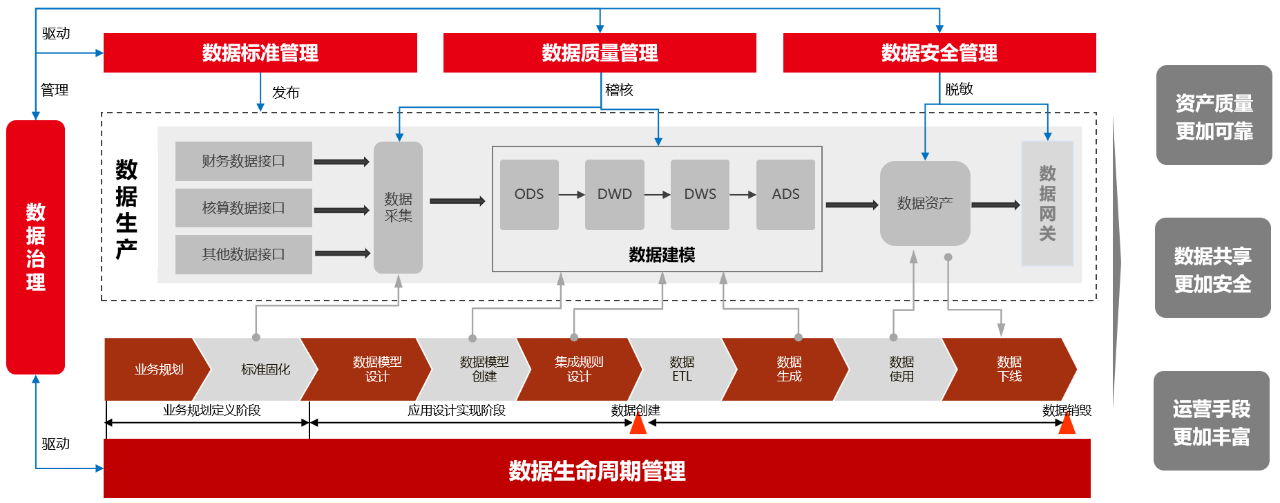
同时针对数据安全治理中数据分级分类、敏感数据识别、数据脱敏管理等关键难点问题,用友IUAP数据治理工具提供一体化的支持,帮助企业建立完善的数据安全体系,确保数据使用安全合规。

1、数据分级分类:企业往往困惑如何对数据进行合理分级分类。用友IUAP数据治理工具预置了丰富的数据分级分类策略模板,综合业务主题、数据结构、访问对象、开放范围等多个维度提供数据分级分类智能提示,帮助企业快速构建符合自身数据管控要求的数据分级分类策略,减少了企业摸着石头过河的时间,有效促进数据资产化。
2、敏感数据识别:随着数据爆发式增长,企业拥有的数据量很有可能到TB甚至PB、EB级别。通过传统手工方式进行敏感数据的梳理和识别,显然工作效率不高且难以保障全面性、准确性。用友IUAP数据治理工具采用智能算法,支持中英文智能匹配敏感数据特征,实现敏感数据的自动识别,极大提升敏感数据识别的效率、全面性和准确性。并基于数据血缘技术,可以快速定位敏感数据流向,让数据资产和安全风险可见。
3、数据脱敏管理:数据脱敏不仅要执行数据漂泊,抹去数据中的敏感内容,还要保持原有数据的特征,有一定的技术难度。用友IUAP数据治理工具内嵌掩码、截断、哈希、加密等多种脱策略,利用先进技术对敏感数据进行保护,防止敏感数据泄露。同时基于大数据引擎优化加密算法,有效提升海量数据脱敏的处理性能。
最后,数据安全治理,人人有责。通过大家的共同努力,齐心协力构建数据安全防火墙,有效保护企业数据资产,为数据要素激活、释放数据价值保驾护航!
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2024
01/04
19:48
分享
点赞

机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
