
面向证券公司电子数据存证的区块链服务平台
探索区块链技术在电子数据存证场景的应用
近年来,金融监管部门先后出台《证券基金经营机构信息技术管理办法》与《证券期货业科技发展“十四五”规划》。随着区块链技术的出现,社会各行各业都在积极探索区块链技术的应用场景。西南证券在综合考虑监管部门要求与自身发展后,由首席信息官牵头制定了《西南证券科技规划蓝图报告》,促进科技与业务的相互融合,构建了面向证券公司电子数据存证的区块链服务平台。
平台建设路径
具体实现上,将公司业务数据分类为流式数据与批次数据。流式数据重点面向持续性的、极少有结束逻辑的业务数据流,例如现金理财产品的交易,客户会频繁地进行现金理财的申购与赎回,没有周期性或固定间断;并且客户几乎不会终结现金类理财产品的购买协议。批次数据重点面向数据量庞大、有相对固定间隔的数据,例如每日新增的电子合同信息汇总、清算信息等。
在业务场景上,选取了公司资管业务下的一款货币基金产品,以流式数据的角度将该产品的销售业务流程划分为9个步骤,每个步骤均从客户的行为角度与公司的响应结果角度对业务数据进行描述;例如客户的操作时间、操作IP、身份认证结果,公司的电子合同/协议信息、交易确认结果等。通过将同一客户在业务办理过程中,由不同步骤产生的业务数据按照时间顺序排序,形成展业过程中完整的证据链,完成流式数据的存证。
对于批次数据,我们选取了每日所有新增的电子协议与合同信息,将电子协议的流水号、客户电子签名等信息在固定时间上链,完成批次数据的存证。
除了公司本地区块链系统中的存证,还将相同数据在行业中心机构区块链系统--上交所发布的“上证链”,与司法机构区块链系统--杭州互联网法院发布的“杭互链”均进行了存证。通过将本地链、行业链、司法链三者的上链功能抽象化,可实现同一份数据加密一次、上链一次、异步并行上链的效果,为其他上市公司对接司法链提供可行性的验证。
平台建设架构与内容
对于公司存证平台的数据加密部分,选择了国密加密算法,采用SM2、SM3进行非对称加密与哈希计算,实现了在相同密钥长度下,更强的加密保护性,满足证券公司的数据合规要求。

图1司法链出证示例
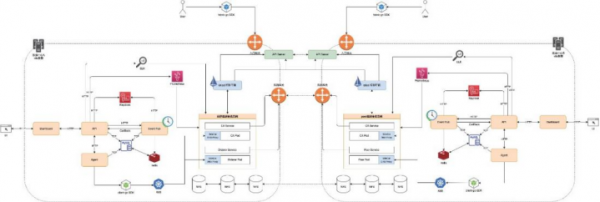
图2云原生架构
平台采用了基于Kubernetes的云原生技术架构,并根据证券公司系统保障要求在不同机房搭建了两个Kubernetes集群,使用Kubefed技术组成联邦集群。各功能模块采用微服务架构建设,集群间服务通信采用了多主架构部署的云原生网关lstio,中间件采用跨机房集群式部署。基于以上技术选型,实现了机房级别的容灾,避免了因单一机器甚至单一机房不可用时对系统造成影晌。
平台设计了权限服务、模板服务、区块链管理服务、上链服务等功能模块。对于流式数据,通过模板服务可以定制化配置不同的逻辑步骤与数据模板,实现任意流式数据的自定义;从而完成面对不同业务时,对业务步骤与存证数据进行自由定义与选择。
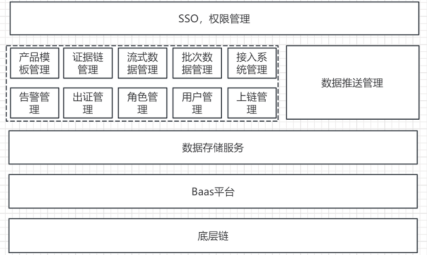
图3功能架构
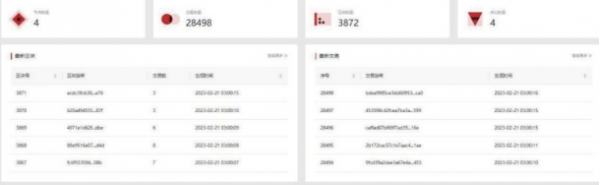
图4区块链管理服务
图4为区块链管理服务的统计图,通过区块链管理服务,可以对公司本地区块链系统进行操作与管控,可直观反映本地区块链系统的运行状况。
平台建设成果
本案例是区块链技术在公司的首次落地,通过探索区块链技术与电子数据存证的方式,成功设计并完成了通用的电子数据存证方法,并从流式数据与批次数据的角度对公司业务数据做了区分。平台建成后,预计每年的电子数据存证量将超过100万笔。
该平台成功对接外部司法链“杭互链”和行业链“上证链”,在进一步提升数据存证效力的同时,为后续的区块链技术合作打下了基础。结合该平台,未来可深入探索公司其他业务与区块链技术的结合,利用区块链的技术特性探索创新场景,助力公司数字化转型。
好文章,需要你的鼓励


Albertsons借助Databricks构建零售商品智能决策平台
美国连锁超市巨头Albertsons正在基于Databricks构建商品智能平台,整合产品、定价、促销与陈列等决策功能,目标是在2026年底前全面向门店运营商落地。该平台以Databricks Lakehouse存储零售数据,通过Unity Catalog与AI Gateway实现数据治理,并借助AI智能体Genie支持自然语言查询,帮助商家洞察销售趋势,提升决策效率。此举是Albertsons今年四项AI核心战略投资之一。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

微软正式将 Windows 11 打造为 AI 操作系统
微软正将Windows 11打造成真正的AI操作系统。在Build大会上,微软展示了AI模型与智能代理如何深度融合进Windows 11,让用户通过自然语言完成系统操作。借助Windows ML框架,超过5亿台PC已可在本地离线运行AI任务,无需联网、无token费用、数据不离设备。Office、Photos、Teams等应用已支持本地AI能力,Adobe、WhatsApp、Canva等第三方也在积极跟进,企业级AI PC采购需求有望加速。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2023
12/22
00:03
分享
点赞

Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
OpenAI携手Trail of Bits发起"Patch the Planet"开源安全修复计划
公共电力性价比优势面临多年来最严峻考验
