
东兴证券智能信用管理平台
随着上市公司数昼的增多和注册制改革的全面铺开,融资融券标的证券和可充抵保证金证券范围迅速扩大,证券公司的融资融券业务规模和客户数量呈现快速增长的趋势,这使得证券公司风险管理的压力和难度大幅增加。券商对两融标的券风险识别及客户持仓证券的风险把控能力对两融业务顺利开展愈发重要。
目前证券行业信用业务担保证券及标的证券管理、同一客户管理、压力测试、舆情管理、客户交易目的识别等仍然以人工为主,难以实现标准化、个性化、精细化等管理,难以满足业务发展需要,且存在一定的操作风险,效率也难以保障。为协助证券企业高效掌控信用业务风险全貌,东兴证券结合知识图谱及机器学习等技术,全新研发智能信用管理平台(以下简称“平台”)。
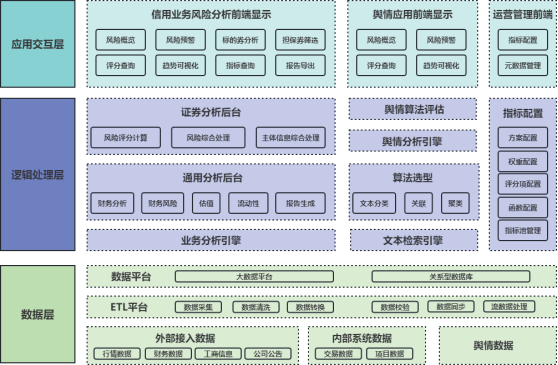
图:智能信用管理平台
平台从下到上,分别为数据层、逻辑处理层和应用交互层。
数据层,负责数据的获取清洗和存储。将各类型的外部数据源数据适配到智能信用业务分析系统标准数据格式。
逻辑处理层,按照业务逻辑和指标配置方案,基于数据层提供的数据,利用Al分析引擎对证券风险进行评估、执行舆情分析评估。
应用交互层,使用者可以通过前端显示和平台进行交互,用户可以通过前端界面与平台进行交互,也可以利用灵活的配置方案和权重参数,定制自己需要的分析方案,以更好地满足业务需求。
平台构建证券分析、证券参数管理自动化、客户风险画像、压力测试、智能舆情五大应用场景。
其一,证券分析。通过平台建立证券评分模型,从证券的流动性风险、估值风险、财务风险和舆情风险等方面按照权重进行评分。在证券评分基础上映射出证券的折算率,可对证券的折算率实现精准的动态定期管理。在系统的辅助下,证券分析采用的指标可灵活挑选,并可根据当前行情趋势进行调整,灵活性及效率都大幅增高。
其二,证券参数管理自动化。建立灵活的担保证券范围及折算率、标的证券范围及保证金比例自动化调整模型,从交易层面、基本面、舆情等方面综合分析、评估,自动生成调整建议、调整公告、导入模板,人工复核后即可进行导入及发布。通过这种方式,操作效率大幅提高并极大减少人为错误。
其三,客户风险画像。基于大数据和人工智能技术,建立科学、有效的模型。通过模型测算客户的风险情况,根据客户资产情况、负债情况、交易特点、收益率等进行综合分析,对客户风险进行预警。平台还可以根据自定义指标对客户投资目标进行识别及分类管理。
其四,压力测试。平台可根据公司两融客户整体持仓情况,实现对单一标的、单一客户、同一客户、全体客户等口径压力测试。平台可对公司客户维持担保比例的区间分布情况进行统计分析,为业务人员提供应对极端情况所需的决策依据。
其五,智能舆情。采用业内领先的Al算法,基于深度学习及自然语言处理等多项先进技术,对信用业务担保券及质押标的券的舆情新闻进行抽取分析。此外,亦能够挖掘实体之间的关联关系,对风险较大证券进行监控,并及时做出调整处理。
智能信用业务管理平台基于行业领先的Al工程化能力、Al算法与分析模型,让业务风险更有效可控,运营更高效精准。平台使用数字化技术和自动化调整模型,提高操作效率、减少人为错误,从而降低企业的生产经营成本,同时通过对客户风险画像功能,根据客户资产、负债、交易、收益等综合分析,提供客户风险程度的评估,提高信用担保产品的质量,
帮助证券公司更好地了解客户风险和监测风险,减少风险损失,提高经济效益,增加企业收益。
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2023
12/19
18:18
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
