
NVIDIA Jetson Nano 2GB 系列文章(31):DeepStream 多模型组合检测1
前面已经介绍过关于 DeepStream 各种输入源的使用方式,而且 Jetson Nano 2GB 上开启 4 路输入(两个摄像头+两个视频文件),都能得到 25FPS 以上的实时性能,但毕竟“单一检测器(detector)”检测出来的物件是离散型的内容,例如车、人、脚踏车这些各自独立的信息。有没有什么方法能够实现“组合信息”呢?例如“黑色/大众/SUV 车”!
DeepStream 有一个非常强大的功能,就是多模型组合检测的功能,以一个主(Primary)推理引擎(GIE:GPU Inference Engine)去带着多个次(Secondary)推理引擎,就能实现前面所说的功能。
本实验在 Jetson Nano 2GB 上,执行 4 种模型的组合检测功能,能将检测到的车辆再往下区分颜色、厂牌、车种等进一步信息,在 4 路输入视频状态下能得到 20+FPS 性能,并且我们将显示的信息做中文化处理(如下图)。
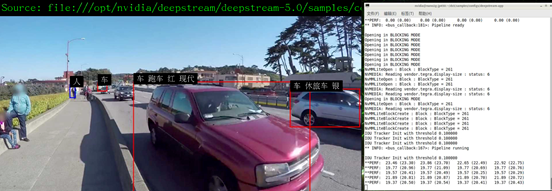
|
nvidia@nano2g-jp450:/opt/nvidia/deepstream/deepstream/samples/models$ ls -l 总用量 24 drwxrwxrwx 2 root root 4096 7月 13 23:49 Primary_Detector drwxrwxrwx 2 root root 4096 7月 13 22:45 Primary_Detector_Nano drwxrwxrwx 2 root root 4096 2月 8 21:50 Secondary_CarColor drwxrwxrwx 2 root root 4096 2月 8 21:50 Secondary_CarMake drwxrwxrwx 2 root root 4096 2月 8 21:50 Secondary_VehicleTypes drwxrwxrwx 4 root root 4096 2月 8 21:49 Segmentation |
简单说明一下每个目录所代表的的意义
- Primary_Detector:作为项目的主检测器,这是用 Caffe 框架以 ResNet10 网络所训练的 4 类检测器,能检测“Car”、“Bicycle”、“Person”、“Roadsign”四种物件,这个数据可以在目录下的 labels.txt 中找到。
- Primary_Detector_Nano:将Primary_Detector里的模型,针对 Jetson Nano(含 2GB)的计算资源进行优化的版本。
- Secondary_CarColor:车子颜色的次级检测器
- Secondary_CarMake:生产厂商的次级检测器
- Secondary_VehicleTypes:车子种类的次级检测器
组成结构也十分简单,其中主(Primary)检测器只有一个,而且必须有一个,否则 DeepStream 无法进行推理识别。次(Secondary)检测器可以有好几个,这里的范例就是针对“Car”这个类别,再添加“Color”、“Maker”、“Type”这三类元素,就能获取视频图像中物件的更完整信息。
在 Jetson Nano 的
/opt/nvidia/deepstream/deepstream/samples/config/deepstream-app 下面的 source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt,就已经把这个组合检测器的配置调试好,现在直接执行以下指令:
|
cd/opt/nvidia/deepstream/deepstream/samples/config/deepstream-app deepstream-app -c source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt |
现在看到启动四个视频窗,但是每个视窗的执行性能只有 8FPS,总性能大约 32FPS,并不是太理想。
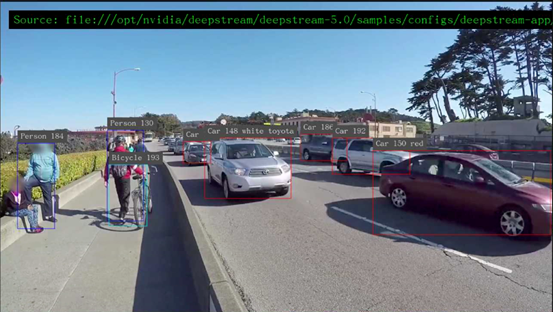
接下来看看怎么优化这个配置文件
- 首先要执行模型组合功能功能,必须把“tracker”功能打开,不过可以关闭追踪号的显示,因此保留“enable=1”,将下面的“display-tracking-id=”设为“0”
- 由于我们在 Jetson Nano 2GB 版本上进行实验,需要进行以下的调整。如果您要在 AGX Xavier 或 Xavier NX 上上执行的活,请忽略这个步骤。
修改主检测器[primary-gie]的模型:配置文件中预设的是“Primary_Detector”检测器,这里得修改成专为 Nano 所训练的版本,这里修改以下几个地方:
(1) model-engine-file路径的“Primary_Detector”部分改成“Primary_Detector_Nano”
(2) config-file 的文件改成 config_infer_primary_nano.txt
因为 Jetson Nano(含2GB)并不支持 int8 计算精度,因此还需要做以下修改:
(3) 将“_b4_gpu0_int8.engine”改成“_b8_gpu0_fp16.engine”
(4) 将所有“xx_gpu0_int8.engine”改成“xx_gpu0_fp16.engine”
3. 将追踪器从原本的 ibnvds_mot_klt.so 改成 libnvds_mot_iou.so,用“#”变更注释的位置就可以。
修改完后重新执行,可以看到每个窗口的检测性能提升到 10~12FPS,总性能提升到 40~48FPS,比原本提升12~50%,不过距离理想中的 25FPS 还有很大的差距。
执行过程中如果遇到“Theremay be a timestamping problem, or this computer is too slow.”这样的信息,就把[sink0]下面的“sync=”设定值改为“0”就可以。
现在看看是否还有什么可调整的空间?参考前一篇文章“DeepStream-04:Jetson Nano 摄像头实时性能”所提到的,将[primary-gie]下面的“interval=”设定为“1”,然后再执行应用时,发现每个输入源的识别性能立即提升到 20FPS 左右(如下图),总性能已经能到 80FPS 左右,比最初的 32FPS 提升大约 2.5倍,这已经很接近实时识别的性能。
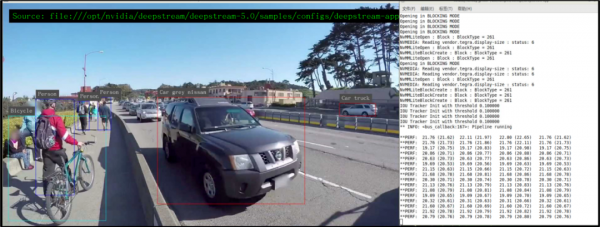
好了,在Jetson Nano 2GB 上已经能达到接近实时推理的性能,是相当好的状态。
如果对于显示输出的状态有些不满意的话,我们按照下面的步骤去执行,将“英文”类别名改成“中文”,并且将边框变粗、字体放大,就能更轻松看到推理的效果:
1. 所有的显示名称,都在 models 目录下个别模型目录里的labels.txt,可以将里面的内容全部改成中文。
例如
deepstream/samples/models/Secondary_CarMake的“labels.txt”内容改为“广汽;奥迪;宝马;雪佛兰;克莱斯勒;道奇;福特;通用;本田;现代;英菲尼迪;吉普;起亚;雷克萨斯;马自达;奔驰;日产;速霸路;丰田;大众”,其他的就比照办理。
注意:这个顺序不能改变!
2. 边框宽度:修改[osd]下面的“board-width”值,推荐 2~4 比较合适;
3. 字体大小:修改[osd]下面的“texe-size”值,推荐 15~18 比较合适;
4. 其他:请自行设定
现在重新执行这个 deepstream-app 的应用,就能得到本文一开始所显示的效果:
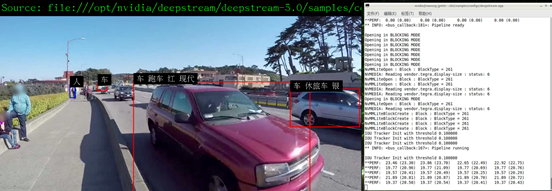
如何?这样的效果与性能就是在 Jetson Nano 2GB 实现的!
来源:至顶网CIO与CTO频道
好文章,需要你的鼓励


FERC要求NERC为数据中心等计算负载制定强制可靠性标准
美国联邦能源监管委员会(FERC)于7月16日发布命令,要求北美电力可靠性公司(NERC)在2026年12月31日前,针对数据中心、加密货币矿场等计算负荷制定强制性电网可靠性标准。此前,NERC已观察到大型数据中心负荷引发电网不稳定事件,并于2026年5月发布最高级别警报。FERC指出,自愿性时间表无法提供足够确定性,必须以强制联邦要求取代,以应对AI数据中心驱动的前所未有的负荷增长对电网可靠性构成的威胁。

广东人工智能研究院开发的“图像创作指挥家“,能像大厨一样编排十几种视觉工具完成复杂图片任务
广东人工智能研究院提出CanvasAgent,通过编排11种专业视觉工具,将复杂图像创作任务拆解为可执行的多步操作,并配套构建了14万条SFT轨迹数据和1万条RL任务规格的CanvasCraft数据集。

西子洁能加快美国燃机余热锅炉订单,24年NE技术合作接住数据中心供电需求
今天讲的出海案例是西子洁能,这家余热锅炉制造商依托24年美国NE技术合作,加快北美燃机余热锅炉订单转化。

当学术写作遇上AI“大管家“:Bibby AI如何把研究者从工具切换的泥潭中解救出来
Bibby AI是一个原生集成编辑器、编译器、文献检索和AI智能体的学术写作平台,将碎片化的研究工具链压缩为单一系统,并引入专利引用信号衡量文献技术影响力。
2021
09/14
17:39
分享
点赞

西子洁能加快美国燃机余热锅炉订单,24年NE技术合作接住数据中心供电需求
印度罚款惠普14亿卢比:墨盒、碳粉与PC"串谋"价格操纵
可口可乐旗下Fairlife乳品公司遭勒索软件攻击,被迫停产
从上海到世界:WAICA正以“AI原生”范式重写顶会规则
从主机节点到异构机架:重新思考AI CPU
苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
