
Jetson Nano 2GB 系列文章(27):DeepStream简介
NVIDIA所提供的开发资源,大多属于库(library)或API级别,包括CUDA、CUDNN、CuFFT、CuBLAS、TensorRT等,需要具备足够的C++/Python编程语言基础的开发人员。
才有能力发挥GPU/CUDA的并行计算优势,这个特性某种程度限制了并行计算相关应用的普及。
DeepStream是一套集NVIDIA最尖端技术精髓于一身的智能视频分析(Intelligent Video Analytics)套件,从深度神经网络和其他复杂的处理任务引入到流处理管道中,以实现对视频和其他传感器数据的接近实时分析工作。

DeepStream在很多的城市管理项目中,扮演最核心的视频分析角色。上图左方是部署在家庭、街道、停车场、购物中心、仓库、工厂中的上百万个摄像头。
通过深度学习的智能技术,快速提取特定的信息并回传至控制中心,能在指定范围中提供安全监控机制,也能提高总体营运的效率。
目前已实现的应用包括访问控制、防止丢失、自动结帐、监视、安全、自动检查(QA)、包裹分类(智能物流)、交通控制/工程、工业自动化等。
要解决上述繁杂场景的效率问题,不仅每个环节的性能要发挥到极致,更重要的是工作流上每个节点的平衡,因为这牵涉到总体性能的分配问题。
下图是DeepStream标准工作流,表示在“单一设备”上所执行的8个步骤,每一步骤都需要配套的计算资源进行处理,任何一段的处理不当都会影响总体性能,因此“平衡”是非常关键的考量。

下面简单介绍一下每个步骤的工作重点(依照从左至右的顺序):
COLLECT:可对接各种数据源,包括摄像头(CSI、USB、GigE接口等)、存储设备(硬盘、SSD等)的视频/图像档案、网络路由器所传入数据等等。
DECODE:进行解码,这个过程传统上非常消耗CPU资源,但目前NVIDIA的很多设备上都提供硬件解码器(DECODER)与算法,能针对不同输入源/视频格式进行快速解码动作,不仅兼容性高,并且能大幅度减轻CPU的负担。
PRE-PROCESS:这个环节中,大部分需要结合OpenCV以及NVIDIA MultiMedia API做大量的格式转换(如RGB转BGR、HSV颜色空间等)、数学转换计算(如Hough转换、Canny检测等)等。这些计算具备明显的并行化特性,也是CUDA/GPU十分擅长的部分。
可以看到这个区块上方绿色部分有个“CUDA”字眼,表示CUDA在扮演重要角色。
TRACK INFERENCE:追踪推理环境,是整个DeepStream中性能影响最大的部分,重度依赖于NVIDIA TensorRT推理引擎的FP16/INT8性能提升能力。T
ensorRT这个推理引擎也是NVIDIA在边缘计算应用中一个非常关键的底层加速API,其本身并不是一个深度学习的框架,但是能支持绝大部分常用的神经网络与框架所训练出来的模型,并将这些模型转换成TensroRT加速的引擎,功能十分强大。
ENCODE:将推理过后的结果进行编码,包括物件识别后的物件位置(色框)、类别、可信比例(confidence)等,转换成后续进行视觉化显示的格式。
COMPOSITE:将多种AI计算后的结果(车型识别、颜色识别、车牌识别等)进行合成,提供给下一阶段进行数据分析。
ANALYZE DATA:这部分的重点,在于“使用者需要进行哪些方面的分析”。目前比较明显的案例是用在特定场所的车流、人流统计数据。
VISUALIZE:视觉化输出,可以根据使用环境的GPU显示功能进行显示屏数量的调整,目前NVIDIA设备的显示功能都能输出多个 4K 质量的画面。
以上是完成单机应用的工作流,如果满足于单一设备的应用,那么下图所提供的技术,就能协助您通过互联网技术。
将分散在各地的DeepStream应用端所获取的特定(物件)信息汇到控制中心,甚至由控制中心对指定(组)DeepStream设备下达动作指令,这才是真正AIOT的完整架构。
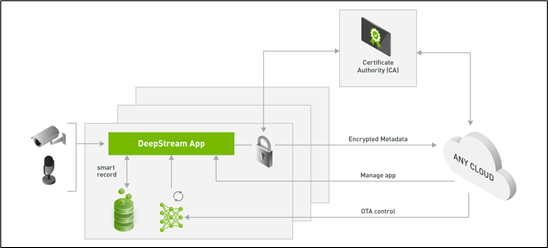
对于实际的IVA应用程序/服务部署,应用程序的远程管理和控制至关重要,DeepStream SDK可以在任何云和边缘运行,这使得它成为处理物联网需求的强大SDK,如边缘和云之间的有效双向消息传递、安全、智能记录和空中AI模型更新。
结合以上的技术,能实现智能视频分析的网上应用托管任务,并且可以轻松部署、升级DeepStream的应用环境。
因此DeepStream不仅追求单机上的极致性能,还添加以下实现AIOT应用的支撑技术,主要包括以下两大部分:
1. 双向通讯与云服务:
(1) 支持Kafka、MQTT和AMQP等物联网集成接口
(2) 支持AWS物联网和Microsoft Azure物联网的交钥匙功能。
(3) 通信安全机制:提供基于SSL证书的双向TLS认证和基于公钥认证的加密通信
(4) 使用双向物联网消息传递功能触发使用DeepStream的特定事件记录
(5) 通过边缘和云之间的双向消息传递,可以添加对用例的更大控制,例如用于事件记录 的远程触发器、更改操作参数和应用程序配置或请求系统日志。
2. 应用部署与管理:
(1) OTA空中更新:从任何云注册中心对整个应用程序或单个人工智能模型,进行无缝更新。
(2) 可以使用NVIDIA NGC容器构建的高性能DeepStream云本机应用程序。
(3) 通过使用DeepStream,可以大规模部署并使用Kubernetes和Helm Charts管理容器化应用程序
(4) DeepStream应用程序中的智能记录功能允许通过选择性记录在边缘上节省宝贵的磁盘空间,从而实现更快的搜索能力。可以使用云到边缘消息快速触发来自云的录制。
下图是DeepStream的软件栈(software stack)图,底层CUDA-X部分负责处理单机上的计算性能,中间DEEPSTREAM SDK的部分则更加重视“通讯”与“部署”两大部分,最上层的可以看出目前主要提供的接口有Python与C/C++两种。
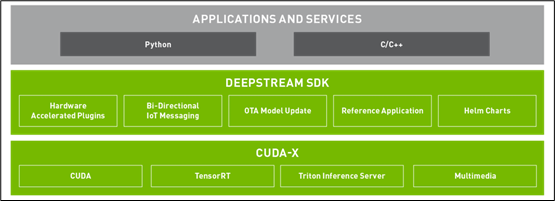
对于初学者的最大好消息是,即便不懂Python或C/C++开发语言,也能很轻松地使用这套视频分析工具。下一篇文章就会带您在NVIDIA Jetson Nano 2GB开发套件中,无需任何编程代码的能力,就可以体验DeepStream强大的功能。
来源:至顶网CIO与CTO频道
好文章,需要你的鼓励


FERC要求NERC为数据中心等计算负载制定强制可靠性标准
美国联邦能源监管委员会(FERC)于7月16日发布命令,要求北美电力可靠性公司(NERC)在2026年12月31日前,针对数据中心、加密货币矿场等计算负荷制定强制性电网可靠性标准。此前,NERC已观察到大型数据中心负荷引发电网不稳定事件,并于2026年5月发布最高级别警报。FERC指出,自愿性时间表无法提供足够确定性,必须以强制联邦要求取代,以应对AI数据中心驱动的前所未有的负荷增长对电网可靠性构成的威胁。

广东人工智能研究院开发的“图像创作指挥家“,能像大厨一样编排十几种视觉工具完成复杂图片任务
广东人工智能研究院提出CanvasAgent,通过编排11种专业视觉工具,将复杂图像创作任务拆解为可执行的多步操作,并配套构建了14万条SFT轨迹数据和1万条RL任务规格的CanvasCraft数据集。

西子洁能加快美国燃机余热锅炉订单,24年NE技术合作接住数据中心供电需求
今天讲的出海案例是西子洁能,这家余热锅炉制造商依托24年美国NE技术合作,加快北美燃机余热锅炉订单转化。

当学术写作遇上AI“大管家“:Bibby AI如何把研究者从工具切换的泥潭中解救出来
Bibby AI是一个原生集成编辑器、编译器、文献检索和AI智能体的学术写作平台,将碎片化的研究工具链压缩为单一系统,并引入专利引用信号衡量文献技术影响力。
2021
09/14
17:32
分享
点赞

西子洁能加快美国燃机余热锅炉订单,24年NE技术合作接住数据中心供电需求
印度罚款惠普14亿卢比:墨盒、碳粉与PC"串谋"价格操纵
可口可乐旗下Fairlife乳品公司遭勒索软件攻击,被迫停产
从上海到世界:WAICA正以“AI原生”范式重写顶会规则
从主机节点到异构机架:重新思考AI CPU
苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
