
混闪配置 全闪性能 感受新华三存储怪兽Nimble的速度与激情
关于全闪存,
江湖中流传着一句箴言……
天下武功,唯快不破!
全闪存的价值在哪里?
答案就是一个字,快!
不过,存储系统的“快”,
可以有很多种解读。
存储系统最常见的性能指标就是IOPS了,也就是每秒进行读写(I/O)操作的次数。不过, IOPS高,就代表性能高吗?这里,我们还需要看另一个性能指标——时延。在存储系统尤其全闪存系统IOPS动辄数十万甚至上百万的今天,时延,才是存储系统性能的终极决胜点。
权威调研公司Gartner认为,在评估存储系统实际使用性能时,应“避免盲目追随厂商声称的毫无意义的数百万IOPS;而应该将低时延作为闪存存储最主要的性能指标。 ”( 摘自2017年7月17日Gartner报告《Critical Capabilities for Solid-State Arrays》)
对用户来说,时延已经超过IOPS和带宽,日益成为了限制业务速度的最大存储瓶颈,而在有效降低时延的基础上,如何实现最佳的存储TCO,更成为所有IT厂商的挑战。
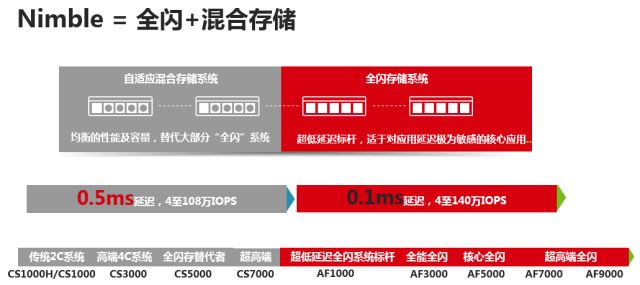
可否采用更高性价比的存储介质,实现全闪存级别的时延呢?新华三集团(以下简称H3C)在2018年1月全面发布的闪存存储产品Nimble(CS混合存储+AF全闪存储),正是从这个设计思路而来。
Nimble可以使用混合阵列的配置,完美的跑出全闪存阵列的IOPS和时延,很好的诠释了什么叫做性能与成本兼顾。
具体如下图所示,Nimble的全闪存阵列可以跑出0.1ms的时延,将业内全闪存的时延标准大幅提升了5~10倍(业内主流全闪存产品时延0.5ms~1ms不等)。但是更加令人震惊的是,Nimble的混合存储可以以超高的性价比实现0.5ms的时延,达到业内主流全闪存产品的时延标准!!!
Nimble系列
笔者刚刚得知这个消息的时候,内心里其实是拒绝的。什么?一堆普通的HDD加上寥寥的3块SSD做读加速,就可以在全随机的情况下赶超全部由SSD组成的全闪存阵列的性能?
不过后来深入了解了其实现原理,笔者只能说:至于你信不信,反正我信了!
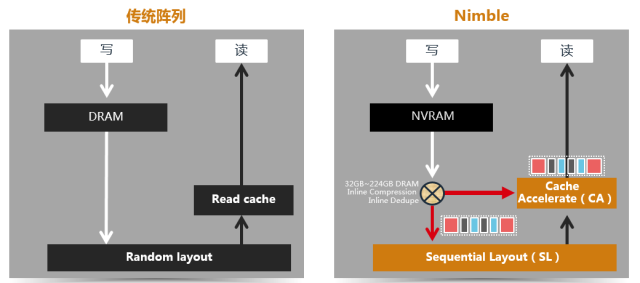
采用NVDimm和硬盘顺序化布局技术,全面优化写性能
对于传统混合阵列而言,有两个随机写的瓶颈点一直没有得到有效的解决:
HDD的随机写入性能有限(最好的HDD随机性能只有200IOPS/块,时延6ms以上),无法很快的将DRAM的数据下刷到HDD,导致DRAM很快被写满。一旦DRAM被写满,那存储系统的性能完全则受限于硬盘的数量。但即使加再多HDD提升IOPS,也仍然无法提升时延的表现;
快照、重删、压缩等已经是当前存储界的标准软件功能,但绝大多数传统阵列开启重删、压缩功能时,都会严重的影响业务性能表现。部分产品开启这些高级功能后,甚至会衰减60%以上的性能,结果是这些炫目的企业级高级功能只可远观不可亵玩焉,实在是令人痛心!
Nimble针对这个痛点,创新型的实现了HDD的随机写入顺序化技术(Sequential Layout,以下简称SL),可以使得每块HDD的性能表现由随机的200IOPS飙升到数万,提升足足100倍之多,如果说DRAM是一个水池,以往的HDD是一根又一根的小水管的话,那使用SL技术的HDD就变成了比以往粗100倍的大水管,可以非常快速的将DRAM的数据写入到后端,从而避免了DRAM被写满。因此,SL结合NVDimm技术,使得Nimble混合存储的随机写入可以达成全闪存的性能及时延。
同时,Nimble的重删、压缩、快照等高级功能都是由额外专属的CPU和DRAM在存储内部进行,无需占用对前端服务器提供性能的DRAM和CPU资源,因此,Nimble可以做到开启重删、压缩等功能,性能零衰减!
采用热点数据智能表技术,全面提升读性能
同样的,对于传统混合阵列而言,随机读的瓶颈点也一直没有得到有效的解决:如上所述,HDD的随机读写性能有限,因此绝大多数厂商提供了SSD Cache二级缓存技术,以求提升读的性能。但是无奈,大部分的SSD Cache设计原理是这样的:将新数据直接写入普通HDD介质,待某数据被连续访问若干次后,以数小时至一天为单位将此数据提升到SSD Cache,以提升读性能。
此方法看似美好,但存在一个致命的问题,就是机器学习是有滞后性的!现在这个时代热点数据几乎几小时一变,被动的响应已经无法满足业务的需求,实际统计来看,即使业内领先的SSD Cache技术的命中率,也不过30%而已,我们需要一个可以第一时间以更高命中率响应最新热点的存储技术!
Nimble针对这个痛点,创新型的实现了数据热度表技术。与传统阵列认为所有新数据都是冷数据,等待冷数据慢慢变热不同,Nimble在向后端HDD刷新数据的同时,根据用户选择将20%~100%的新数据全部同步写入SSD Cache,然后根据数据的冷热不同,将冷数据慢慢剔除。实际统计来看,Nimble的SSD Cache技术显著的提升了命中率至少一倍。
综上,Nimble采用CASL技术后,显著的提升了混合阵列的读写性能,并大幅降低了时延,综合表现,Nimble的混合存储时延可以达成和全闪存媲美的0.5ms!
有兴趣的小伙伴们,不妨感受一下Nimble性能小怪兽的速度与激情……
Nimble性能怪兽拥有“快、稳、简、智”四大神技,本期我们对“快”字神技进行了深入解读,下期我们将带来Nimble“稳”字神技的解读,敬请期待……
来源:TechWeb
好文章,需要你的鼓励


至顶AI实验室硬核评测:HP Z2 Mini G1a工作站,仅30分钟还原毛利侦探事务所
真相只有一个:在AI与创意的交汇点上,HP Z2 Mini G1a确实是一台值得推荐的灵感引擎。

德国图宾根大学团队让2D材质预测瞬间“立体化“:MatSpray技术重新定义3D物体重光照
德国图宾根大学研究团队开发了MatSpray技术,能将2D照片中的材质信息准确转换为3D模型的物理属性。该技术结合了2D扩散模型的材质识别能力和3D高斯重建技术,通过创新的神经融合器解决多视角预测不一致问题,实现了高质量的材质重建和真实的重光照效果,处理速度比现有方法提升3.5倍。

我们希望AI有多智能?世界模型可能比我们更懂世界
近年来,AI学会了写作、生成图像、创建视频甚至编写代码。随着这些能力成为主流,研究重点转向更深层问题:机器能否真正理解世界运作方式?世界模型应运而生,从1950年代概念到2024年OpenAI的Sora、2025年英伟达Cosmos等突破性应用。与语言模型基于文本预测不同,世界模型专注预测环境变化,通过学习因果关系实现推理规划。在机器人、自动驾驶等物理AI领域前景广阔,但面临计算资源需求高、数据收集困难等挑战。

纽约大学发明“大脑翻译器“:让机器人读懂人类思维,精准操控语言AI
纽约大学研究团队开发出革命性"大脑翻译器"技术,首次实现用人类大脑活动模式精确控制AI语言行为。通过MEG脑磁图技术构建大脑语言地图,提取20个关键坐标轴,训练轻量级适配器让AI按人脑思维方式工作。实验证明该方法不仅能精确引导AI生成特定类型文本,还显著提升语言自然度,在多个AI模型中表现出良好通用性,为人机交互和AI可控性研究开辟全新路径。
2018
03/22
17:00
分享
点赞

至顶AI实验室硬核评测:HP Z2 Mini G1a工作站,仅30分钟还原毛利侦探事务所
冷板式液冷CDU系统
开箱 NVIDIA DGX Spark: 把一千万亿次算力,“塞进”ipad mini大小的盒子里
我们希望AI有多智能?世界模型可能比我们更懂世界
首席信息官角色将在2026年扩展的四种方式
Waymo正在测试Gemini在无人驾驶出租车中的车载AI助手功能
数据中心从幕后走向台前的转折之年
意大利要求Meta暂停禁止竞争对手AI聊天机器人使用WhatsApp的政策
让老旧Windows和macOS系统延续生命力
微软计划到2030年用Rust语言替换所有C和C++代码
2026年创客工具迎来重大升级,这些新技术值得期待
2025年十大网络故事盘点
